对着眼前黑色支撑的天空 / 我突然只有沉默了
我驾着最后一班船离开 / 才发现所有的灯塔都消失了
这是如此触目惊心的 / 因为失去了方向我已停止了
就象一个半山腰的攀登者 / 凭着那一点勇气和激情来到这儿
如此上下都不着地地喘息着 / 闭上眼睛疼痛的感觉溶化了
--达达乐队《黄金时代》
好几个地方看到这个 Facebook – Needle in a Haystack: Efficient Storage of Billions of Photos,是 Facebook 的 Jason Sobel 做的一个 PPT,揭示了不少比较有参考价值的信息。【也别错过我过去的这篇Facebook 的PHP性能与扩展性】
图片规模
作为世界上最大的 SNS 站点之一,Facebook 图片有多少? 65 亿张原始图片,每张图片存为 4-5 个不同尺寸,这样总计图片文件有 300 亿左右,总容量 540T,天! 峰值的时候每秒钟请求 47.5 万个图片 (当然多数通过 CDN) ,每周上传 1 亿张图片。
图片存储
前一段时间说 Facebook 服务器超过 10000 台,现在打开不止了吧,Facebook 融到的大把银子都用来买硬件了。图片是存储在 Netapp NAS上的,采用 NFS 方式。
图片写入
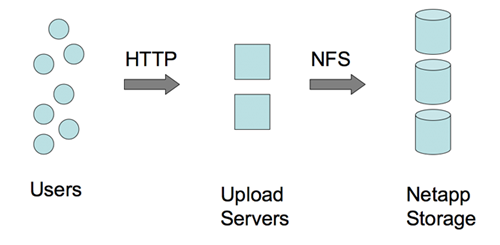
尽管这么大的量,似乎图片写入并不是问题。如上图,是直接通过 NFS 写的。
图片读取
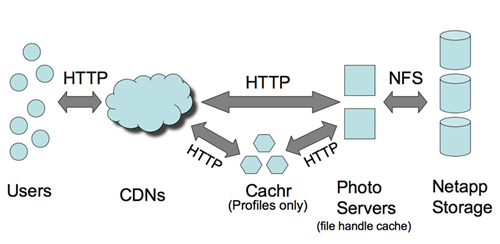
CDN 和 Cachr 承担了大部分访问压力。尽管 Netapp 设备不便宜,但基本上不承担多大的访问压力,否则吃不消。CDN 针对 Profile 图象的命中率有 99.8%,普通图片也有 92% 的命中率。命中丢失的部分采由 Netapp 承担。
图中的 Cachr 这个组件,应该是用来消息通知(基于调整过的 evhttp的嘛),Memcached 作为后端存储。Web 图片服务器是 Lighttpd,用于 FHC (文件处理 Cache),后端也是 Memcached。Facebook 的 Memcached 服务器数量差不多世界上最大了,人家连 MYSQL 服务器还有两千台呢。
Haystacks –大海捞针
这么大的数据量如何进行索引? 如何快速定位文件? 这是通过 Haystacks 来做到的。Haystacks 是用户层抽象机制,简单的说就是把图片元数据的进行有效的存储管理。传统的方式可能是通过 DB 来做,Facebook 是通过文件系统来完成的。通过 GET / POST 进行读/写操作,应该说,这倒也是个比较有趣的思路,如果感兴趣的话,看一下 GET / POST 请求的方法或许能给我们点启发。
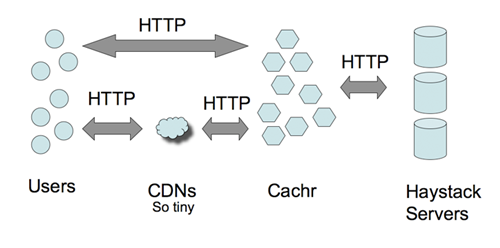
总体来看,Facebook 的图片处理还是采用成本偏高的方法来做的。技术含量貌似并不大。不清楚是否对图片作 Tweak,比如不影响图片质量的情况下减小图片尺寸。
–EOF–
Mysql有2k多台?真是够大的。CDN就差不多搞定了图片访问~
文章不错啊,我转载到业内网了:http://www.iyenei.com/show.php?tid=367
Facebook – Needle in a Haystack: Efficient Storage of Billions of Photos
我最近也在研究大数据量的存储,没有flawgram的注册码?
能否发一份给我[email protected]
3x
@sailor
不用邀请,直接看的
需要比较快的网络
amoeba:分布式数据库Proxy解决方案
可以在上面需要一种可线性扩展得sql规则。从而可以达到数据库线性扩展。
具体文档下载 http://amoeba.sf.net/amoeba.pdf
amoeba 不是陈思儒搞得么?
这个是who的留言啊?
@Sky
那位同学好像就是陈思儒
最近准备解析oracle协议
amoeba 以后可能会支持 后端各种数据库
big picture
http://amoeba.sf.net/amoeba-big-picture.pdf
@struct
:) 厉害的
^_^, 多谢各位大师,以后在amoeba for oracle方面还希望各位大师指点啊
其实后端可以考虑CAS设备,访问速度更快
恩写的不错很好.收藏了谢谢.
这个数据分析的很透彻,不知道能不能海量的抓取后台数据,也就是数据库的东西,希望能够抓取到........
NFS是旧的方案,已经被抛弃了,原因是NFS层支撑不住大量的metadata访问开销,即使简单的stat获取ST_SIZE提供Content-Length对fb海量图片来说都很大了。而这些meta信息在OS层是有缓存的,只是fb图片量数量太大,导致缓存能力跟不上,为此fb增加了一层cache专门处理元数据,仍旧无法根本解决问题
为此,facebook实现了Haystack存储图片,本质上Haystack是个对象存储。Haystack主要用于存储图片文件,避免了海量琐碎小文件在文件系统中inode开销以及metadata访问开销。
在Haystack Object Store和HTTP Server中间有一层Photo Store用于缓存metadata(内存中),直接解决了之前NFS架构的metadata访问开销问题。
至于在Haystack中存储metadata一个很大原因是便于Photo Store快速加载。
原始链接: http://www.facebook.com/note.php?note_id=76191543919