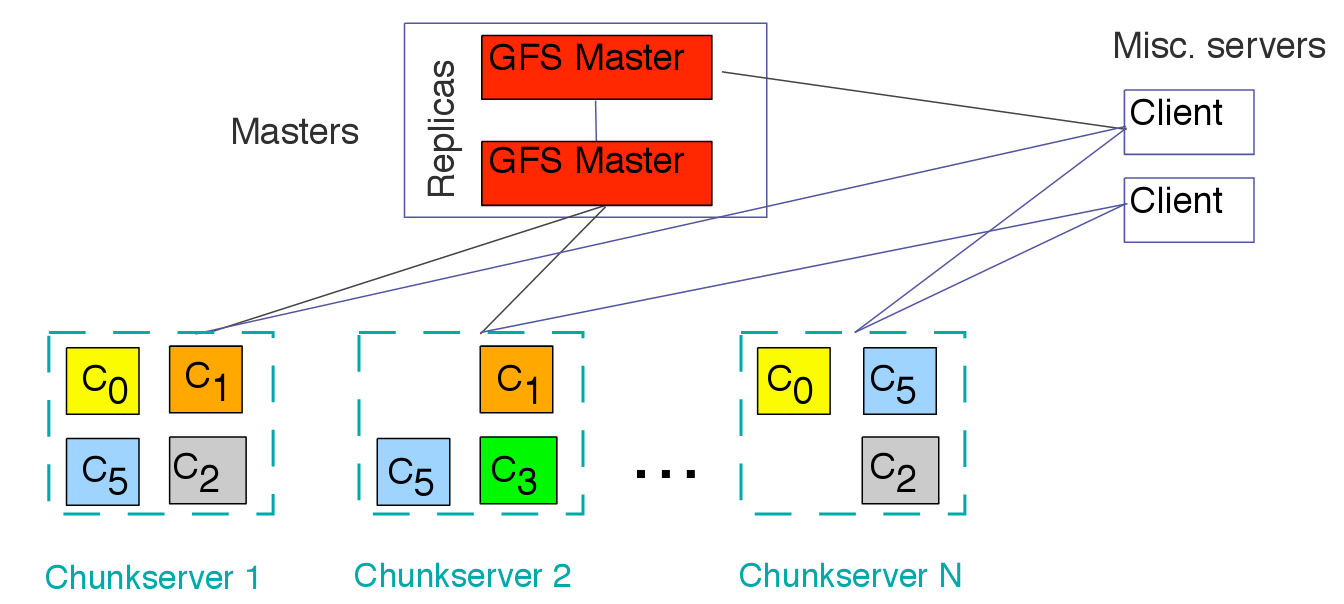
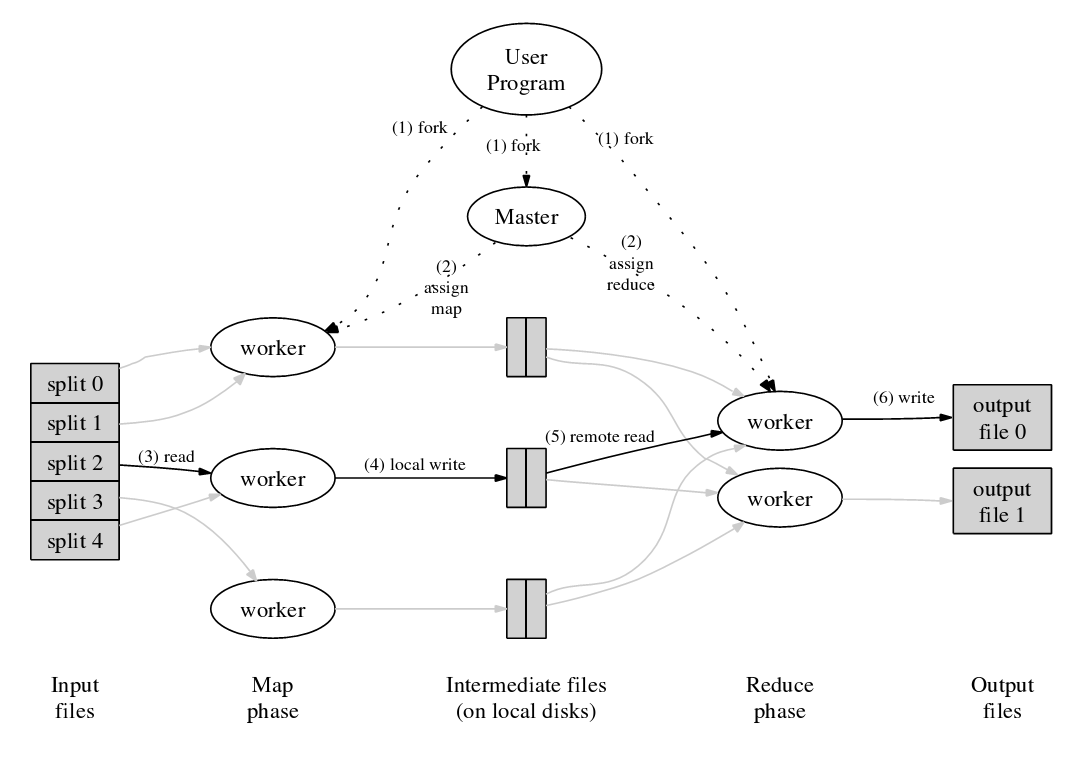
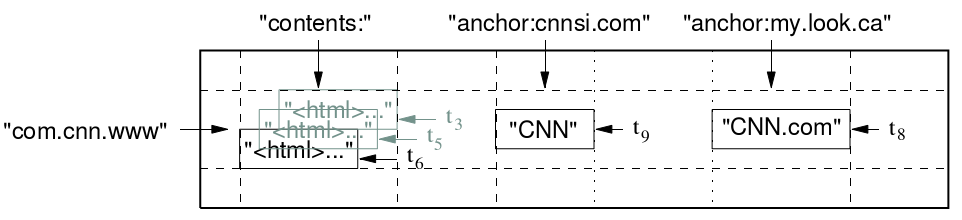
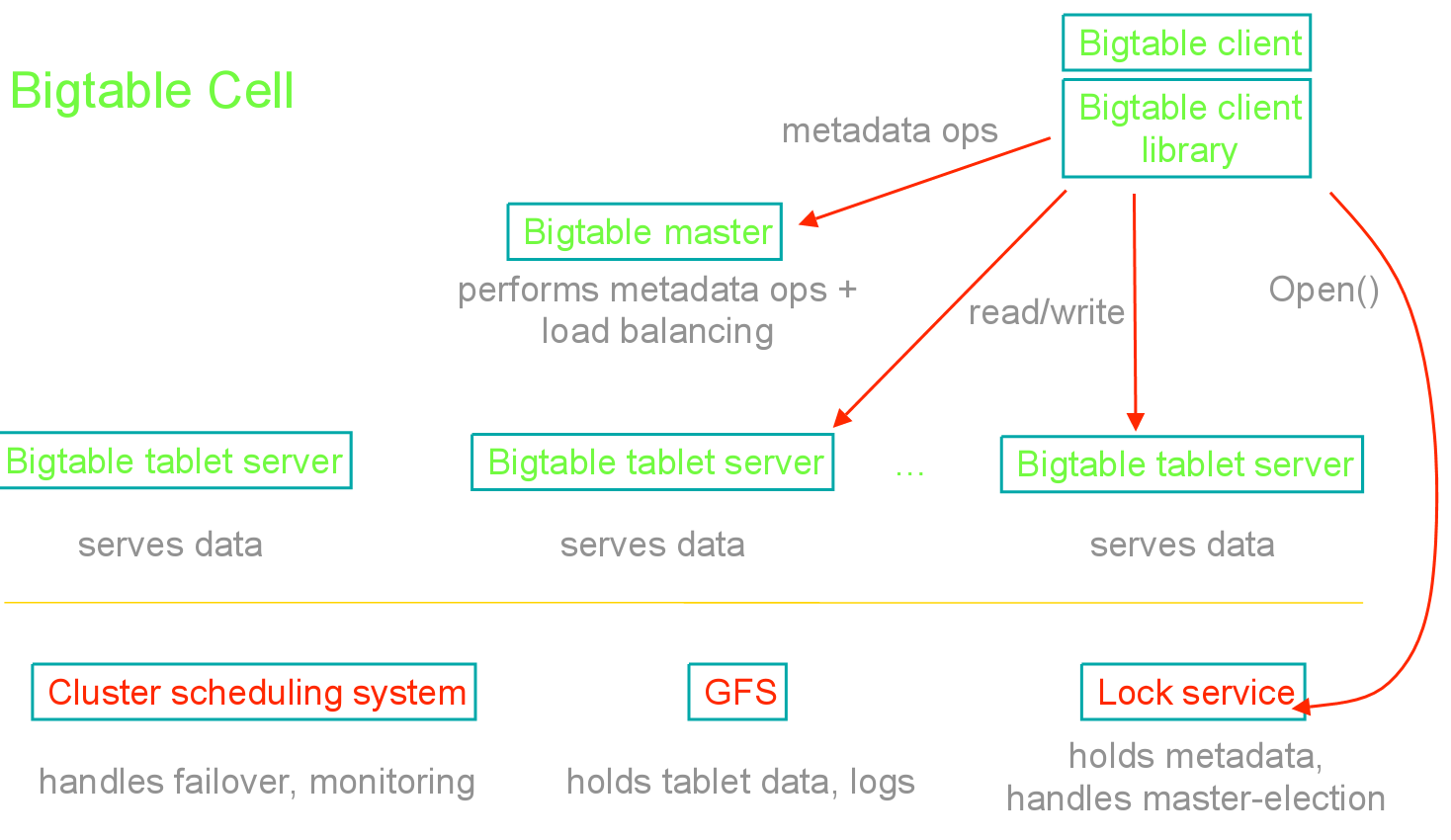
按:此为客座博文系列。投稿人吴朱华曾在IBM中国研究院从事与云计算相关的研究,现在正致力于研究云计算技术。
本文是基于现有的公开资料和个人的经验来对Google的整体架构进行总结和猜想。
在软件工程界,大家有一个共识,那就是”需求决定架构”,也就是说,架构的发展是为了更好地支撑应用。那么本文在介绍架构之前,先介绍一下Google所提供的主要产品有哪些?
产品
对于Google和它几个主要产品,比如搜索和邮件等,大家已经非常熟悉了,但是其提供服务的不只于此,并主要可分为六大类:
- 各种搜索:网页搜索,图片搜索和视频搜索等。
- 广告系统:AdWords和AdSense。
- 生产力工具:Gmail和Google Apps等。
- 地理产品:地图,Google Earth和Google Sky等。
- 视频播放:Youtube。
- PaaS平台:Google App Engine。
设计理念
根据现有的资料,Google的设计理念主要可以总结出下面这六条:
- Scale,Scale,Scale Scale:因为Google大多数服务所面对的客户都是百万级别以上的,导致Scale也就是伸缩已经深深植入Google的DNA中,而且Google为了帮助其开发人员更好地开发分布式应用和服务,不仅研发了用于大规模数据处理MapReduce框架,还推出了用于部署分布式应用的PaaS平台Google App Engine。
- 容错:一个分布式系统,就算是构建在昂贵的小型机或者大型机之上,也会不时地出现软件或者硬件方面的错误,何况Google的分布式系统还是浇筑在便宜的X86服务器之上,即使其设备标称的MTBF(平均故障间隔时间)很高,但是由于一个集群内的设备极多,导致其错误发生的几率非常高,比如李开复曾经提过这样一个例子:在一个拥有两万台X86服务器的集群中,每天大约有110台机器会出现宕机等恶劣情况,所以容错是一个不可被忽视的问题,同时这点也被Google院士Jeffrey Dean在多次演讲中提到。
- 低延迟:延迟是影响用户体验的一个非常重要的因素,Google的副总裁Marissa Mayer曾经说过:”如果每次搜索的时间多延迟半秒的话,那么使用搜索服务的人将减少20%”,从这个例子可以看出,低延迟对用户体验非常关键,而且为了避免光速和复杂网络环境造成的延时,Google已在很多地区设置了本地的数据中心。
- 廉价的硬件和软件:由于Google每天所处理的数据和请求在规模上是史无前例的,所以现有的服务器和商业软件厂商是很难为Google”度身定做”一套分布式系统,而且就算能够设计和生产出来,其价格也是Google所无法承受的,所以其上百万台服务器基本采用便宜的X86系统和开源的Linux,并开发了一整套分布式软件栈,其中就包括上篇提到的MapReduce,BigTable和GFS等。
- 优先移动计算:虽然随着摩尔定律的不断发展,使得很多资源都处于不断地增长中,比如带宽等,但是到现在为止移动数据成本远大于移动计算的成本,所以在处理大规模数据的时候,Google还是倾向于移动计算,而不是移动数据。
- 服务模式:在Google的系统中,服务是相当常用的,比如其核心的搜索引擎需要依赖700-1000个内部服务,而且服务这种松耦合的开发模式在测试,开发和扩展等方面都有优势,因为它适合小团队开发,并且便于测试。
整体架构的猜想
在整体架构这部分,首先会举出Google的三种主要工作负载,接着会试着对数据中心进行分类,最后会做一下总结。
三种工作负载
对于Google而言,其实工作负载并不仅仅只有搜索这一种,主要可以被分为三大类:
- 本地交互:用于在用户本地为其提供基本的Google服务,比如网页搜索等,但会将内容的生成和管理工作移交给下面的内容交付系统,比如:生成搜索所需的Index等。通过本地交互,能让用户减少延迟,从而提高用户体验,而且其对SLA要求很高,因为是直接面对客户的。
- 内容交付:用于为Google大多数服务提供内容的存储,生成和管理工作,比如创建搜索所需的Index,存储YouTube的视频和GMail的数据等,而且内容交互系统主要基于Google自己开发那套分布式软件栈。还有,这套系统非常重视吞吐量和成本,而不是SLA。
- 关键业务:主要包括Google一些企业级事务,比如用于企业日常运行的客户管理和人力资源等系统和赚取利润的广告系统(AdWords和AdSense),同时关键业务对SLA的要求非常高。
两类数据中心
按照2008年数据,Google在全球有37个数据中心,其中19个在美国,12个在欧洲,3个在亚洲(北京、香港、东京),另外3个分布于俄罗斯和南美。下图显示其中36个数据中心在全球的分布:
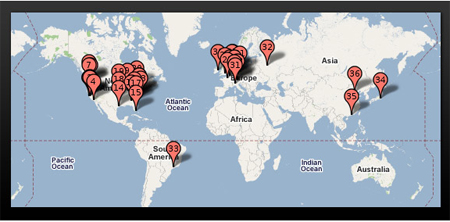 图1. 2008年Google全球数据中心分布图
图1. 2008年Google全球数据中心分布图
根据 Jeffrey Dean 在2009年末的一次演讲和最近几期季报可以推测出Google并没有在2009年过多地增加全球数据中心的数量,总数应该还是稍多于36个,但很有可能在台湾、马来西亚、立陶宛等地增加新的数据中心。
虽然Google拥有数据中心数量很多,但是它们之间存在一定的差异,而且主要可以分为两类:其一是巨型数据中心,其二是大中型数据中心。
巨型数据中心:服务器规模应该在十万台以上,常坐落于发电厂旁以获得更廉价的能源,主要用于Google内部服务,也就是内容交付服务,而且在设计方面主要关注成本和吞吐量,所以引入了大量的定制硬件和软件,来减低PUE并提升处理量,但其对SLA方面要求不是特别严厉,只要保证绝大部分时间可用即可。下图是Google巨型数据中心的一个代表,这个数据中心位于美国俄勒冈州北部哥伦比亚河畔的Dalles市,总占地面积接近30英亩,并占用了附近一个1.8GW水力发电站的大部分电力输出,当这个数据中心全部投入使用后,将消耗103兆瓦的电力,这相当于一个中小型城市的整个生活用电。

图2. Google在美国俄勒冈州哥伦比亚河畔的巨型数据中心近景图
大中型数据中心:服务器规模在千台至万台左右,可用于本地交互或者关键业务,在设计方面上非常重视延迟和高可用性,使得其坐落地点尽可能地接近用户而且采用了标准硬件和软件,比如Dell的服务器和MySQL的数据库等,常见的PUE大概在1.5和1.9之间。本来坐落于北京朝阳区酒仙桥附近的”世纪互联”机房的Google中国数据中心也属于大中型数据中心这类,其采用的硬件有DELL的工作站和Juniper的防火墙等,下图为其一角。

图3. Google前中国数据中心的一角(参[26])
关于两者的区别:具体请查看下表:
| 巨型数据中心 | 大中型数据中心 | |
| 工作负载 | 内容交付 | 本地交互/关键业务 |
| 地点 | 离发电厂近 | 离用户近 |
| 设计特点 | 高吞吐,低成本 | 低延迟,高可用性 |
| 服务器定制化 | 多 | 少 |
| SLA | 普通 | 高 |
| 服务器数量 | 十万台以上 | 千台以上 |
| 数据中心数量 | 十个以内 | 几十个 |
| PUE估值 | 1.2 | 1.5 |
表1. 巨型与大中型数据中心的对比表
总结
最后,稍微总结一下,首先,普通的用户当访问Google服务时,大多会根据其请求的IP地址或者其所属的ISP将这个请求转发到用户本地的数据中心,如果本地数据中心无法处理这个请求,它很有可能将这个请求转发给远端的内容交互中心。其次,当广告客户想接入Google的广告系统时,这个请求会直接转发至其专业的关键业务数据中心来处理。
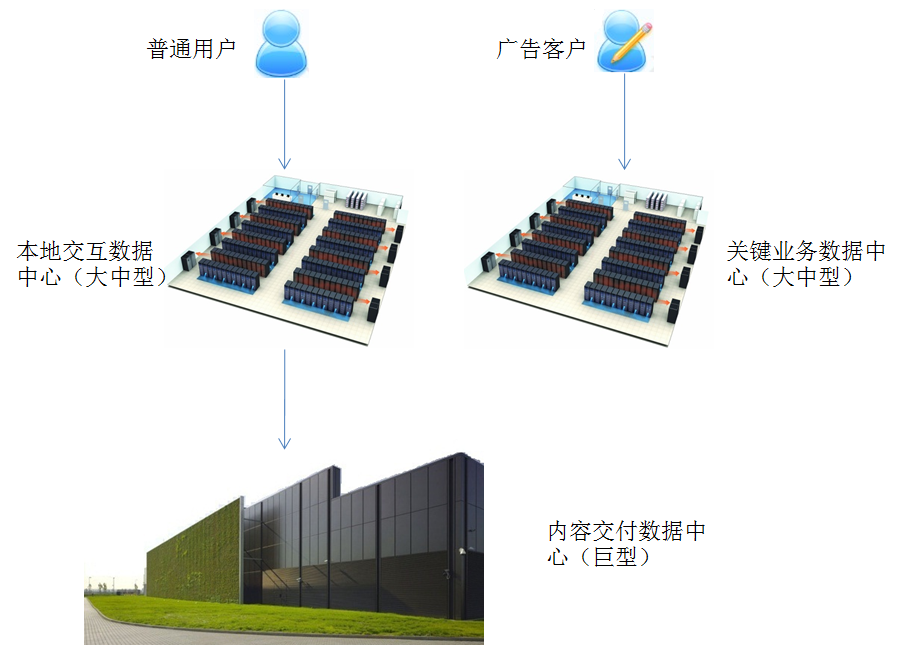
图4. 总结
因为本文是基于现有的公开资料和个人的经验的总结和猜想,所以和Google实际的运行情况没有任何联系。
本篇结束,下篇将对Google App Engine及其主要组成部分进行介绍。
–EOF–