Technorati (现在被阻尼了, 可能你访问不了)的 Dorion Carroll在 2006 MySQL 用户会议上介绍了一些关于 Technorati 后台数据库架构的情况.
基本情况
目前处理着大约 10Tb 核心数据, 分布在大约 20 台机器上.通过复制, 多增加了 100Tb 数据, 分布在 200 台机器上. 每天增长的数据 1TB. 通过 SOA 的运用, 物理与逻辑的访问相隔离, 似乎消除了数据库的瓶颈. 值得一提的是, 该扩展过程始终是利用普通的硬件与开源软件来完成的. 毕竟 , Web 2.0 站点都不是烧钱的主. 从数据量来看,这绝对是一个相对比较大的 Web 2.0 应用.
Tag 是 Technorati 最为重要的数据元素. 爆炸性的 Tag 增长给 Technorati 带来了不小的挑战.
2005 年 1 月的时候, 只有两台数据库服务器, 一主一从. 到了 06 年一月份, 已经是一主一从, 6 台 MyISAM 从数据库用来对付查询, 3 台 MyISAM 用作异步计算.
一些核心的处理方法:
1) 根据实体(tags/posttags))进行分区
衡量数据访问方法,读和写的平衡.然后通过不同的维度进行分区.( Technorati 数据更新不会很多, 否则会成为数据库灾难)
2) 合理利用 InnoDB 与 MyISAM
InnoDB 用于数据完整性/写性能要求比较高的应用. MyISAM 适合进行 OLAP 运算. 物尽其用.
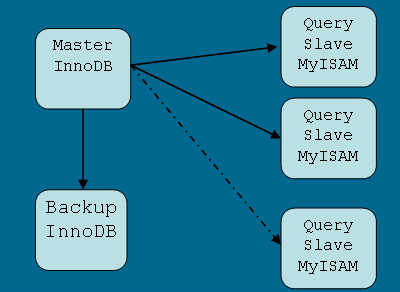
3) MySQL 复制
复制数据到从主数据库到辅数据库上,平衡分布查询与异步计算, 另外一个功能是提供冗余. 如图:
后记
拜读了一个藏袍的两篇大做(mixi.jp:使用开源软件搭建的可扩展SNS网站 / FeedBurner:基于MySQL和JAVA的可扩展Web应用) 心痒难当, 顺藤摸瓜, 发现也有文档提及 Technorati , 赶紧照样学习一下. 几篇文档读罢, MySQL 的 可扩展性让我刮目相看.
或许,应该把注意力留一点给 MySQL 了 .
–End.
长见识了>.
没想到,mysql有这么的厉害,一直担心它到了tb级就瘫痪了。下次我可以试试。
mysql同步一旦slave损坏,恢复同步是个很痛苦的过程,数据越多越痛苦
10Tb 核心数据, 分布在大约 20 台机器上.通过复制, 多增加了 100Tb 数据, 分布在 200 台机器上. 每天增长的数据 1TB.
2005 年 1 月的时候, 只有两台数据库服务器, 一主一从. 到了 06 年一月份, 已经是一主一从,
似乎数字有错??
10Tb 核心数据, 分布在大约 20 台机器上.通过复制, 多增加了 100Tb 数据, 分布在 200 台机器上. 每天增长的数据 1TB.
2005 年 1 月的时候, 只有两台数据库服务器, 一主一从. 到了 06 年一月份, 已经是一主一从,
似乎数字有错?? — 是不是作者没有认真校对?
一个是总数据, 一个是关于 Tag 的数据
mysql不会哦
您的博客顶强,以后多来学习下!
好文,收藏至20ju.com
复制数据到从主数据库到辅数据库上,平衡分布查询与异步计算, 另外一个功能是提供冗余.但是是否提供了负载均衡的功能呢?
楼主强 多学习复制数据到从主数据库到辅数据库上,平衡分布查询与异步计算, 另外一个功能是提供冗余.但是是否提供了负载均衡的功能呢?
楼主 多学习复制数据到从主数据库到辅数据库上,平衡分布查询与异步计算, 另外一个功能是提供冗余.但是是否提供了负载均衡的功能呢?
一个是总数据, 一个是关于 Tag 的数据
一个是总数据, 一个是关于 Tag 的数据
Pingback: 各大型网站架构分析收集 | 小样儿(ShowYounger)