这次 QCon (北京)会议网站架构案例分析这个 Track ,虽然话题不多,但课程设计时候考虑覆盖的面还是比较广的。作为视频网站代表,优酷带来了一场包含不少实战经验的技术分享。邱丹(优酷网开发副总裁,核心架构师)可能公司的事情比较忙,一直到第二天中午才赶到会场。还半开玩笑说,’怎么这么多人,还以为是小型的会议呢’…

缓存
缓存黄金原则:让数据更靠近 CPU。
CPU-->CPU 一级缓存-->二级缓存-->内存-->硬盘-->LAN-->WAN
讲到了 Youku 自己的内部项目,针对大文件缓存的。目前开源软件中,Squid 的 write() 用户进程空间有消耗,Lighttpd 1.5 的 AIO(异步I/O) 读取文件到用户内存导致效率也比较低下。Youku 不用内存做缓存(避免内存拷贝,避免内存锁)。值得注意的是,缓存技术容易被滥用,也有副作用,比如接到老大哥通知要把某个视频撤下来,如果在缓存里是比较麻烦的。
数据库
优酷对数据库 Sharding 做了不少尝试,而且实现效果应该不错。DB 读写分离上有比较丰富的经验。
为了提升数据库 I/O 能力,启用了 SSD 。6 块 SSD 做 RAID 。我在 Twitter 上发了一则 Youku 使用了 SSD 的消息,很多朋友以为是用来存储视频文件,这里需要澄清一下–只是局部使用。
网络吞吐量优化
这是我强烈要求加上来的一节内容。网络优化,视频网站肯定都做得不错。这一节的关键词是 “事件(event)驱动”,令人深刻的一句话是 “ePoll 推动当今 Web” ,的确,现在很多比较热的 Web 组件都是以 ePoll 为卖点。
延伸阅读: The C10K problem (我一直想翻译一下这个页面,苦于腾不出时间) 与 Libevent 如果做互联网,遇到扩展性问题,这两个信息点还是避不过去的。
最后一个例子是针对 Memcached 的 Agent 的,这一点和 Facebook 架构中的 Memcached 处理可以对照来看。
演讲结束的时候,有人提问优酷对视频缓存上有什么特别的地方? 回答是一个大视频可能分成多个小文件,这样缓冲的时候就效果更好一点–(并行啦)…其实访问优酷的确比土豆快那么一点点。
–EOF–
PPT 过几天 InfoQ 中文站会发布。稍安勿躁。
ePoll到底是什么?到底能搞什么?
似乎涉及到linux 内核了,没有细看
“一个大视频可能分成多个小文件” —-主要目的是为了节省带宽,优酷的下载并不是多线程的。比土豆快的原因主要在于CDN建设的好。
SSD上跑数据库的话,应该是利用0寻道时间的优势来支撑起读操作吧,如果连写操作都用SSD,如何保证SSD寿命问题?没法去北京现场,不知道是否涉及了这个话题?
epoll是linux下的一个函数了。
一开始是select,后来变成了poll。然后epoll有要代替poll拉。
这次会的内容好像非常丰富阿
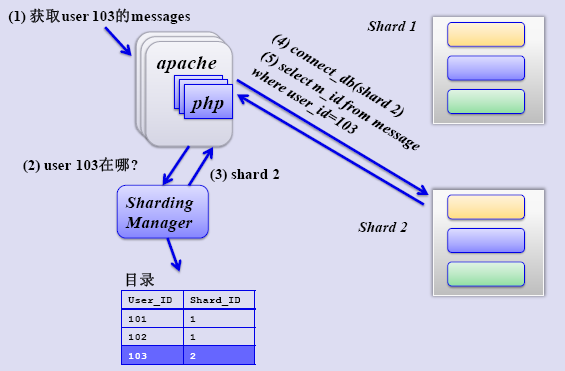
数据库
优酷对数据库 Sharding 做了不少尝试,而且实现效果应该不错。DB 读写分离上有比较丰富的经验。
这张图看上去。难道还要去查询下user103所在的库位置?
这不是多了一步查询吗?意义不大。
epoll能改变原来select方式对大连接的问题。对网络本身的吞吐量没啥改进吧。
好文,收藏至20ju.com
TO 冷烟:
那样做,比较灵活吧。用户可以轻易的在不同的shard之间迁移。
不错的会场,又是在哪个五星级宾馆么?
不需要把原视频分段也能够分段下载啊。
如果说效果好,指的是拖拉的话,还说得过去(这样flv的metadata也是分段下载好的了,不需要统一等前面的下载完)
好文,收藏之,以后继续拜读楼主的大作!
如果说效果好,指的是拖拉的话,还说得过去(这样flv的metadata也是分段下载好的了,不需要统一等前面的下载完
这次会的内容好像非常丰富,酷对数据库 Sharding 做了不少尝试,而且实现效果应该不错。DB 读写分离上有比较丰富的经验。
To 冷烟
图中可以看出,他们把用户的资料分散到很多个shared去了。
可以这样考虑:所有用户分享的视频信息总量有1000个盘块。假设查询的时候只会做线性查询。
如果都放在一起,每次查某个视频的信息平均要查500个盘块。
如果按照图里面的方法,假定每个shared最大占50盘块。记录某个用户在哪个shared的表占5个盘块。
第一次查用户信息在哪个shared,平均2.5盘块
第二次查视频信息,平均25盘块
两次查询 一共27.5盘块。
查询是有两次,但可以少查询那么多盘块,提速是非常明显的。