对国内互联网用户来说,OpenDNS.com 这个服务在技术圈子里还是有些知名度的,当然这要归功于国内电信服务商对域名的无耻劫持行为。
OpenDNS 的员工 Richard Crowley 在 Velocity 2009 上和与会者分享了关于 OpenDNS Stats 服务的实现。当时的数据是每天有 140 亿次的 DNS 查询,而现在从公开的数据看,每天已经超过 180 亿次查询。这个 PPT 的内容就是讲 OpenDNS 是如何处理并统计这些查询记录的。
主要的策略分两步,第一步,根据网段切数据;第二步,聚合与存储。体现到 DB 层面是给每个网段单独分配一个表,尽可能的让表更小,让主键更小。
选择合适的方式存储域名。如果表使用 auto_increment 字段做主键是不太合适的做法–不同的引擎都有或多或少的锁问题,OpenDNS 采用域名的 SHA1 摘要值用来做域名的主键(SHA1 是20个字节,倒也不算浪费空间)。用了两台机器,每台 48GB 左右的存储空间,另外通过跨在 8 台机器上总共 28GB 的 Memcached 来避免对数据库的读操作。
对于聚合数据的进程会产生内存溢出的问题,采取的办法是清空内存,重启进程(而不是释放内存)的思路。利用了 supervise 这个小工具来做到。这地方其实值得商榷。
开始曾发现 80% 的 I/O 等待表的打开与关闭上。通过 Strace 发现存在大量的 open() 与 close() 调用。通过設置 ulimit -n 600000 解决(关于 ulimit 参数的意义参考。这意味着 OpenDNS 用了大约 60 万个表(网段)!(?) 这的确是比较极端的做法。
而在 DB 存储引擎的选择开始用了 MyISAM ,也是不合适的,通过迁移到 InnoDB 速度得到了很大提升。这似乎是缺乏评估与规划的表现,或许 OpenDNS 在这方面并非十分擅长。
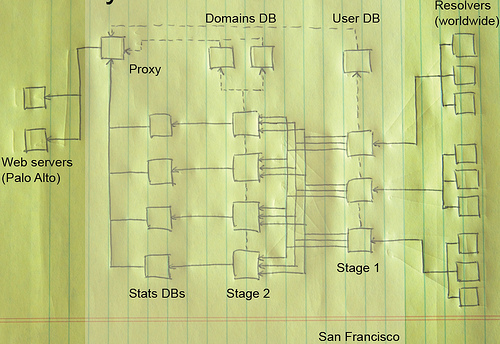
(Copyright by Richard Crowley )
上图从右向左看,查询日志通过 rsync 同步到 Stage 1 的服务器上(位于旧金山),根据查询到的域名把查询日志映射为中间文件,然后把数据文件同步到 Stage 2 的服务器,启动聚合进程把中间文件读入,修剪(Pruning)进程把拼装好的 SQL 语句写入 DB。整个步骤其实暗合 MapReduce 的思路。虽然不是严格的 MapReduce 实现。
听说国内提供类似服务的 DNSPod 因为上次的暴风长老事件受到了广泛瞩目,前不久成立了公司旨在专门提供智能 DNS 服务。不知道每天查询量有多大。[Updated: 见楼下 DNSPod 站长的回复 “DNSPod请求数每天20来个亿” ]
–EOF–
几句题外话:因为逐渐远离一线技术环境,为保持对技术的兴趣,每天多读一些 PPT 也是有乐趣的事情,或许一年没有敲多少条命令,但是看的 PPT 恐怕没有几个人比我多。看到一些还算有趣的 PPT 就做点笔记和大家分享。或许对人有用呢。
Updated:Google 开始提供 DNS 了。Google Public DNS
还可以参考一下这篇:OpenDNS MySQL abuses,另外,Richard Crowley 已经在2010 年2月份从 OpenDNS 离职…
DNSPod请求数每天20来个亿吧,毕竟是授权服务器,和cache服务器差很远。数据统计很久没做了,之前的话是和dns同一台机器上面跑的脚本直接分析出结果后rsync取回到中心服务器,mysql只做存储结果供查询用。看了下最近每20分钟单机也能产生个1G数据,下个阶段会把log分析重新做起来
@奶罩
强烈建议对这些数据做做一些分析,数据不做分析没有价值啊。而一旦分析并且展现出来,就会产生难以估量的影响。
其实远离一线技术环境,是很难跟的上目前的趋势的。不参加一线项目,很容易被淘汰,这就是做技术的命?!
这都是自己选择的,不是命。远离一线技术环境我的理解是用心做管理之类的事情去了。如果一心只关注技术自然就一辈子做技术。
好玩好玩真好玩,OpenDNS还能提供注册用户的请求纪录查询。
自己选择就要勇敢些,呵呵,支持你
Google Public DNS 来了
http://code.google.com/intl/zh-CN/speed/public-dns/
问个问题: sha1算法,怎么是20字节呢?
取的是sha1的部分