这是前一段时间《程序员》杂志采访支付宝架构师团队的的稿件。篇幅较长,此为第二部分。。
本周支付宝架构师团队一部分成员将参加 CSDN 上海英雄会,欢迎做些技术或者业务方面的交流,
尤其是支付宝的一些合作伙伴公司和潜在合作伙伴公司。
书接前文
支付宝每时每刻都要应对海量的数据和交易,是否使用了类似于”云计算”的方式进行后台处理?对于业界现在热炒的”云计算”概念,你们团队有什么想法?
的确,支付宝的数据堪称海量,但相比之下,主要的压力还是来自对交易事务的处理上。我们也有一些密集型的后台计算,但相对规模不算特别大,当前的计算能力足以支撑,当然,我们也尽量会想办法用更小的成本提供更强的计算能力。
对于云计算,我们目前还没找到很合适的应用场景,但整个架构组目前对云计算保持密切的关注,并会投入适当的力量进行一些前瞻性研究。我们实际上更为关注一些解决方案,比如 Hadoop ,并准备在 DW/BI 方面进行一些尝试。
冯大辉曾经在一个访谈中提到:技术架构与产品设计这两者的优劣,会对 Web 应用的发展起到至关重要的作用,那么这二者应该如何平衡?在支付宝进行架构设计和产品设计时,是怎么样进行权衡的?
通常情况下我们的技术架构是可支撑产品设计的多样性需求的,但仍有部分产品设计因市场的差异化需求非常特殊,造成我们的技术架构要支撑这部分产品产生了一定的挑战,这也是因为我们的所处的行业是一个迅速发展的行业有关,一方面我们加强技术架构的灵活性和前瞻性研究,另一方面我们也同时加强对产品设计的规范指导,使其两者达到平衡。
我们在技术架构的发展上做了很多课题性研究,如遇到新产品的设计技术架构无法支撑的情况下我们对产品所带来的收益与需扩展技术架构的投入成本上做出分析权衡.
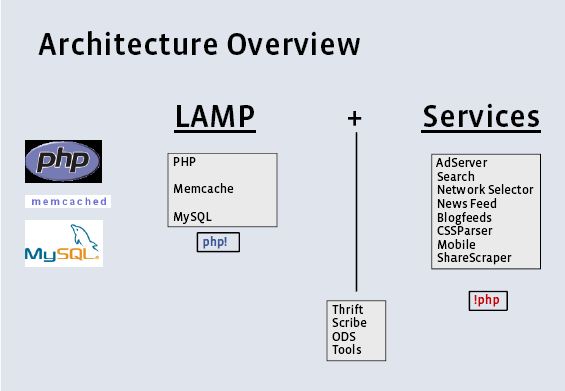
高性能设计中缓存技术是最常用到的,您们在架构设计中通常怎样考虑缓存问题?
现代大型系统中,Cache 是个非产关键的组件,在具体实践中,我们会依据支付宝自身的数据特点对数据部署缓存策略,支付宝对数据实时性的要求造成Cache的准确性要求极高,而数据的私有性造成提高Cache命中率难度较大。客观地说,目前对于 Cache 的利用应该说还不是很充分,这有待于我们进行更深入的研究。
简单的说几点经验,一个是要合理的选择 Cache 所在的位置. 简单的说,Cache 的位置有几个地方:
Web服务器层 -> 应用服务器层 -> 数据库层
具体使用哪个 Cache 以及在哪个位置来做 Cache,要依据缓存什么、性能要求、数据量、可伸缩性、事务要求、过期特性、一致性要求、可复制性、硬件投资、开发投资多个维度来考虑。如果 Cache 的位置选择不合适,那么系统伸缩性会受到严重影响,每次 Cache 系统实施之前,需要架构师进行充分的论证和评估。
第二点,在Cache 存储的资源粒度,需依据 Cache 资源的特点,比如登录者基本信息,就完全可以一次性缓存起来,对于聚合关系结构的业务对象,在缓存的时候需要考虑业务特点,如果业务上对聚合对象内部的对象访问就很频繁,那么就考虑选择小对象力度缓存,否则考虑大粒度对象。第二点是Cache自身的特点,本地JVM Cache,可以考虑存储大对象,因为此时没有网络访问、数据流量的考虑,那么即使业务上小对象访问比较多,也可以考虑完全缓存整个对象关系;如果是远程 cache,那么就要依据大粒度和小粒度对象访问的频率,然后决定。
Cache 是个非常庞大的话题,如有必要,可以选择另外的时间进行探讨。
分布式是架构设计中最有挑战的任务,您们在分布式设计中主要从什么角度出发?怎样选择按用户拆分和功能拆分?
考虑到支付宝的业务特点, 无论我们做什么应用,安全性、可靠性肯定是排在第一位的。然后我们会重点考虑性能和可扩展性。支付宝现在已经是最大的第三方支付工具,日益增长的交易量给架构师们带来了很大的挑战。我们在具体实践中也从BASE 策略中得到很大参考:
Basically Availble --基本可用
Soft-state --软状态(柔性状态)
Eventual Consistency --最终一致性
目前的拆分原则主要是遵循 SOA 的思路,面向服务进行拆分,这也是基本原则之一。 至于是否按照用户拆分,只要不违背 SOA 即可。
对于开放平台、开放 API、以及SaaS这些互联网的新风潮,支付宝架构团队有什么看法?
开放平台这个词最近确实非常火,好像一夜之间大家都开放了。开放确实是一种趋势,任何一个互联网公司都只是整个互联网生态圈中的一环,只有开放才能让自己更好的融入到整个生态圈中。这是大方向,大方向确定了,剩下的事情就是如何开放,开放什么的问题了,这也是每个互联网公司需要仔细考虑的问题。
我觉得随着公司业务的不断发展,开放是一个必然的结果,我们在支付宝创建初期就意识到整个支付市场是非常大的,在服务好淘宝的基础上应该大胆的走出去,去为更多的电子商务平台提供支付服务。所以,我们很早就推出了支付宝商户平台,在这个平台上我们提供了大量的交易、支付服务。通过这几年的运营,我们确实尝到了开放的好处(外部商户为我们的交易量做出了很大贡献),同时我们也积累了很多开放的经验。目前我们正在开发一套新的开放平台,我们希望通过这个平台,可以为我们的合作伙伴提供更多、更好的服务,同时也希望有更多的第三方公司能在我们提供的基础服务之上,创造出新的商业模式。
如果说”面向服务架构”使企业IT系统支持业务敏捷化的话,开放平台则是使互联网大系统支持整个行业生态圈的业务敏捷化。开放平台、是企业追求开放式成长的必然道路,也是SOA原则走出企业系统的狭小圈子、在广袤互联网上的自然延伸。以支付宝的实践来看,在2005年中,支付宝就针对互联网交易提供了API,为互联网上的电子商务提供安全交易与资金流解决方案。随着业务领域不断拓展,原来的从需求->解决方案->产品->API的方式,周期太长,已经难以快速满足大量合作伙伴的需求。因此,支付宝现在正在由产品式的开放转向平台式的开放,通过加强开放基础设施的建设,向合作伙伴提供更基础、更可重用、更体系化的服务,达到与合作伙伴充分协同,建设繁荣、共赢的电子商务生态圈的目标。
同时,开放的业务服务与开放的技术平台也正在推动支付宝的业务与技术架构向前发展,对构建更大规模的分布式系统、更大规模的并行研发模式都带来了积极而深远的影响。
对于有志于成为架构师的开发者,支付宝架构团队有何建议?
技术不是一蹴而就的事情,而是长时间积累的成果。此外,扎实的基本功是做好所有事情的开始!抽象的能力也是作为一名好的程序员必须具备的,我们在考虑问题的时候可能会遇到错综复杂的场景,从这些迷雾中找到一条明路是我们做好程序员的关键。实际抽象能力衍生出来的一点就是需要我们对已学过的知识定期的进行梳理,这样能让你稳固已有的知识,为以后学习的更多的知识做好准备。
实践也是非常重要的一个环节,不要有畏难心里,觉得这个东西非常的难,我无法完成!有时候你去完成一件事情,事情的结果可能会是糟糕的,但是解决这件事情的过程是非常宝贵的,你可以在这个过程中学习到很多东西!最后我还要说一点的是,业务知识非常重要,这个是你实践的关键!(by 胡喜)
架构师在设计系统架构,或者对重大问题进行决策时,必须在全面考虑各种因素、充分前瞻的基础上做出全局最优的选择。这种整体性与发展性的思考模式是一种能力,也是一种习惯,一种态度。作为有志于成为架构师的开发者,应该在日常开发中就养成站在整体、发展的角度去理解、分析、与解决问题的习惯。(by 程立)
再补充三点:
- 1、从程序员到架构师:是思维提升的一个过程、责任心升华的一个过程、是一楼向楼顶攀爬的一个过程,每一层楼,都要向下、向上、向远处看(注:这个楼顶有多高?没人知道 :) ;
- 2、读别人的代码、框架,看身边同事做事情,与同事一起讨论问题等,要始终尝试:交换思想的苹果,达到 1 + 1 > 2 ;
- 3、找一个架构师老师,榨取他身上的每一点优点(别把坏的也给学去了) ;
(by 姚建东)
架构师在成长过程是个顿悟的过程,需要自己注意及时总结,尤其是不可能不犯错误,但是需要自己通过每次所犯的错误进行深刻的总结提升自己。提升的过程是个螺旋式上升的过程,自己以前也做失败过一个案例,至今记忆深刻,通过这次深刻的教训,对自己的成长是很有帮助的。遇到错误不要怕,要坦然面对,能做到:犯错误–>提升–>避免错误就可以了。(by 王学安)
1,架构师往往是领域专家,持续关注领域发展和创新、领域知识,了解领域需求,并将领域需求不断的融入到架构模型里,侧重领域功能布局。
2,架构师往往是技术专家,持续的关注技术知识,架构模式,设计模式以及技术规范等,技术架构关注点可以是,开发高效、复用、安全、可维护可管理、灵活等。
3,实践出真知,持续关注领域、技术,勇于实践。( by 刘明源)
附录:可能有的朋友已经知道支付宝的花名文化,这次接受采访的同事花名可以列一下:鲁肃、苗人凤、西毒、阿玺、邓芝、庞统、夫差、李磊、俊义。(猎头们就别盯着这里看了,做点有技术含量的事儿吧)
–EOF–