这几天给我印象比较深的是 HeroKu ,提供 Ruby 快速部署环境并提供托管能力,他们的架构图做得十分漂亮,一幅图胜过千言万语,要是对 Web 架构感兴趣,都别问架构师了,看看 HeroKu 的架构估计就明白个差不多了 :)
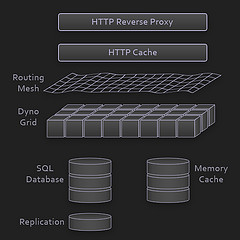
概览图
好的架构图是画出来的,好的架构未必是设计出来的,最后架构好不好,还要看持续的改进能力。
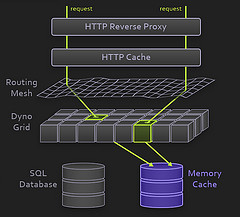
HTTP 反向代理
使用 Nginx , 这一层只进行 HTTP-level 的处理。Nginx 现在是不二选择。
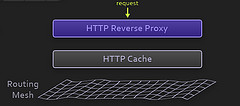
HTTP Cache
对于静态内容,使用 Varnish 进行缓存。如果你在 Squid 和 Varnish 之间作选择,这里已经投了一票。

路由网(Routing Mesh)
用 Erlang 实现的架构组件,路由寻址,用以提升可用性和扩展性。
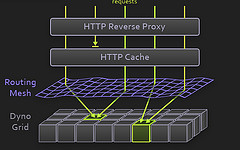
动态网格(Dyno Grid)
用户部署的代码运行在这里,可以简单看成是应用服务器集群环境,只是粒度更小一点而已。
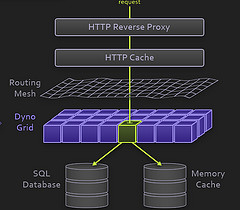
对于 Dyno Grid 的进一步信息:

服务器操作系统是 Debian ;Ruby VM 是 MRI ,开源,C 写的;App Server 用的 Thin,他们说 Thin 比 Mongrel 更精炼;Rack,应用服务器接口;Rack 中间件,可选组件;框架,任何 Rack 兼容的都成;最后是客户托管的代码。
数据库
PostgreSQL,也可以采用远程数据库。
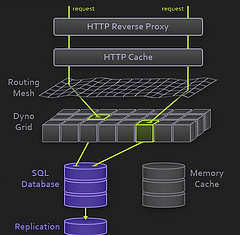
Memory Cache
Memcached ,居家旅行架构必备。
这几张图看下来,多少算是对 Ruby 环境有了一些感性认识。可以进一步查看 HeroKu 提供的文档,包含了一些代码实现上的准则。
部署是基于 Git 的。不知道大家有没有注意到 Git 在最近一年来的爆发? 超过 SVN 或许不是不可能的。
国内热炒”云计算”的,跟人家学学吧,与其整天帮着客户开发定制软件,还不如给客户提供一些弹性应用托管环境,起码看起来靠谱一些。
HeroKu ,不读 Hero-Ku, 读作 Her-oh-koo, 挺有趣
–EOF–
图的来源:HeroKu Platform Architecture


