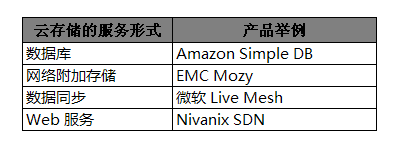
老文。去年受泰稳之托做的采访。这是我整理的稿件。另请参见 InfoQ 中文站上关于 此文的更多信息。
可能 MySQL Proxy 很多数据库技术人员都比较熟悉了,在前不久,国内也有开发者发布了一个Amoeba(变形虫)项目(http://sourceforge.net/projects/amoeba),这个项目专注分布式数据库 Proxy 开发,引起了广泛的关注。 DBA notes( http://www.dbanotes.net ) 站长Fenng 有幸采访了阿米巴项目的开发者陈思儒,以下是采访全文。
Fenng:你好,思儒,很高兴能接受采访,简要介绍一下自己吧?
陈思儒: 我目前是盛大计算机(上海)有限公司的一位高级研究员。 在就业生涯中从事分布式消息系统、分布式应用、多层框架设计、规则引擎开发框架研究,以及 Java 2D MMORPG框架研究。
Fenng: 说一下当初开发 Amoeba 项目的缘由如何,估计其中也会有不少小故事吧? 我可是非常好奇。
陈思儒: 其实 Amoeba 的前身是网络数据包分析代理,之所以 Amoeba 能够快速稳定发展也是因为个人在前期使用这些技术分析过一些游戏的数据包(这儿不方便透露一些细节,这些都只是个人爱好而已,并没有破坏那些被我研究过的游戏 :D )。
为什么会有 Amoeba 这个产品,这个话题的确非常有意思,我关注 MySQL Proxy 也有一段时间了。MySQL Proxy 的这种想法做的非常棒,它能够根据自己的想法去构造目标的 MySQL Proxy 应用,比如监控 SQL 执行、数据流量、读写分离。但由于我们使用 MySQL Proxy 并不能非常轻易的解决一些问题(读写分离、数据切分、水平切分、负载均衡),而是需要写大量的Lua Script,这些 Lua 并不是现成的而是自己需要去写。这个工作对于并不熟悉 MySQL Proxy 内置变量、MySQL Protocol 来说是非常困难的。
因此带着这个想法我就设想做一个非常容易使用、可移植性非常强的软件。Amoeba就因此诞生了。为什么叫Amoeba? 其实这个想法我是突然想到的,Amoeba中文意思是”变形虫”,Amoeba被设想为数据库代理的开发框架,它可以为符合Amoeba框架的任何数据库开发代理层。因此也比较象”变形虫”一样能够变成目标数据库的代理层软件。
Fenng: 我观察到 Amoeba 与 Oracle 交互的时候似乎还是模拟 MySQL 的驱动器, 实际情况是否如此?
陈思儒:目前Amoeba有2个产品:Amoeba for MySQL,Amoeba for Aladdin 。这2个产品有不同的适用范围:
- Amoeba for MySQL:被代理的只有MySQL数据库,需要分析 MySQL网络协议,它的代价比Aladdin会小很多,而且性能也较高;
- Amoeba for Aladdin:被代理的可以是目前提供Jdbc driver的所有数据库,这些数据库可以同时并存于Amoeba for Aladdin后端。
其实在我上一家公司的时候也正在研发 Amoeba for Oracle,这个产品目前还正在研发状态。这个产品性能也跟 Amoeba for MySQL 一样出色。
就 Amoeba for Aladdin 产品来说,后端的任何数据与 Aladdin 交互采用 JDBC Driver. 对于 Aladdin来说,数据库的协议是透明的,而应用跟 Aladdin 的交互则采用 MySQL 协议,这个做法很多人有不明白,其实做这个决定主要是想借助 MySQL 使用的广泛程度以及对各种 开发语言的支持。因此对前端的应用来说 Aladdin 就是一个虚拟的 MySQL 数据库。你这个问题应该是问使用 Aladdin 的时候。
Fenng: 是的,是在看了你的 Aladdin 架构图后产生的疑惑。你比我严谨多了(笑)。能否冒昧问一下 Amoeba 项目当前的局限?
陈思儒:虽然 Amoeba 能够很好的解决水平切分、垂直切分等,但还是会存在一些局限性,这些局限性是因为我们在设计目标的数据库架构的时候就必须考虑到我们未来的数据库框架(可以线性扩容的数据库架构)。因此也有些查询将不支持,比如跨数据库服务器进行Join,我们要尽量避免类似的业务出现,也可以通过多次查询来解决这类问题。
Fenng: 你在前面也说到了 MySQL Proxy,能否简单的说说 Amoeba 与 MySQL Proxy的区别?
陈思儒:其实说与MySQL Proxy的区别应该是Amoeba for MySQL与 MySQL Proxy 的区别,在上面表述的第二点应该都涉及到了:
- Amoeba只是目标数据库代理的开发框架。
- Amoeba for Aladdin 是另外一个类似Amoeba for MySQL的产品。他们共同点是都可以做负载均衡(HA、ROUNDROBIN,WEIGHTBASED)、读写分离、数据切分(垂直、水平)、failOver。
Fenng: 据说你也分析过 Oracle 的 TNS 协议,你认为可靠性如何?
陈思儒:的确,我在上一家公司为做 Amoeba for Oracle 分析过 TNS协议,可靠性以及安全方面都是没什么问题,Oracle 还提供了一些网络层的性能参数,用来改变Oracle的网络吞吐量。但是 Oracle 的数据部封包做法让我和老同事在分析 Oracle 数据包的时候伤透脑筋, 我觉得 Oracle 如果想在协议上面升级版本将不是一件容易的事情。而MySQL 的协议封包的做法我比较赞同。
Fenng: 对于分析 TNS 的可行性,我的看法倒是和你类似。顺便问一下,现在 Amoeba 是否已经有了成功案例, 方便的话能否举几个?
陈思儒:Amoeba for MySQL 的成功案例,目前就网友直接跟我说的有几个,但我还没具体了解他们具体的公司名称,以后知道了我再透露。
Fenng: 到时候千万要通知我一下。对了,能否说一下 Amoeba 项目的愿景以及下一步的目标?
陈思儒:目前距离Amoeba发展目标还有一点距离,Amoeba 未来将是一个更加容易使用、可管理、可动态装载配置、Amoeba集群等。
如果未来可行的话,我将补充 MySQL 协议,做一个用于负载均衡的”重定向路由器”(类似F5功能,但它只是做连接跳转)。
Fenng: 现在开发者主要是你一个人? 是否还有其他维护者 ?
陈思儒:Amoeba 框架、Amoeba for MySQL、Amoeba for Aladdin 目前的开发就我一个人。
Fenng: 很高兴你接受我的采访。期待 Amoeba 项目取得更大的成就,也祝你工作愉快!
陈思儒:客气!也希望有更多的开源爱好者或是数据库技术爱好者加入到这个项目的开发中来。关于 Amoeba 项目的进展我会在 “Amoeba 开发者博客“上更新,欢迎订阅。
–EOF–
旧文重发,期待新的一年这个项目能有更大的发展,能有更多公司从该项目中受益。