拜读了关于 LinkedIn 几位工程师写的构建 TB 级的 key-value 系统的经验:Building a terabyte-scale data cycle at LinkedIn with Hadoop and Project Voldemort。具体实现过程有大致的描述,就不鹦鹉学舌了。
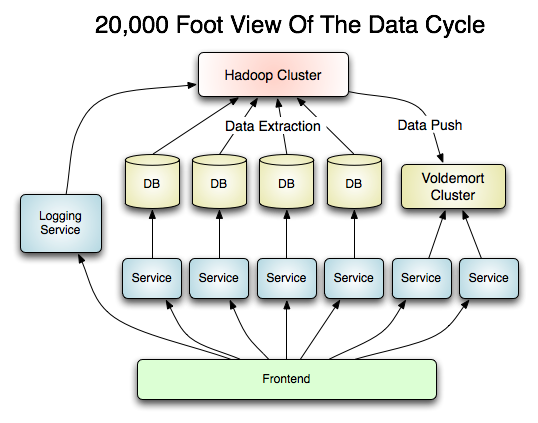
其实现在很多公司可能都面临着这个抽象架构图中的类似问题。以 Hadoop 作为后端的计算集群,计算得出来的数据如果要反向推到前面去,用什么方式存储更为恰当? 再放到 DB 里面的话,构建索引是麻烦事;放到 Memcached 之类的 Key-Value 分布式系统中,毕竟只是在内存里,数据又容易丢。Voldemort 算是一个不错的改良方案。
值得借鉴的几点:
- 键(Key)结构的设计,有点技巧;
- 架构师熟知硬件结构是有用的。越大的系统越是如此。
- 用好并行。Amdahl 定律以后出现的场合会更多。
关于 key-value 应用的解决方案又多了一种。LinkedIn 对此应用案例也还在发展中。如果业务类型类似,不妨关注一下。
–EOF–