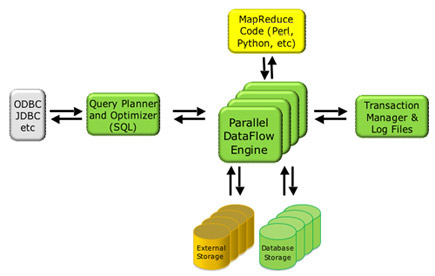
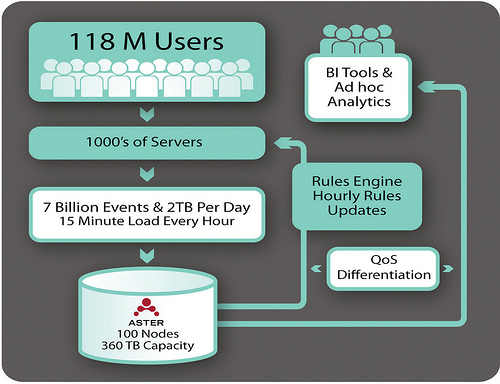
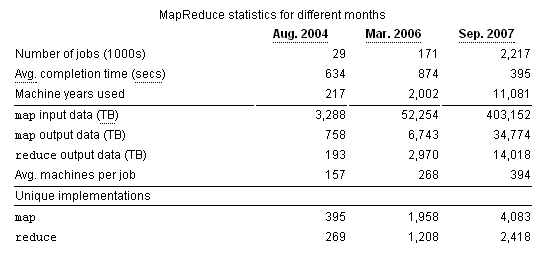
初接触 Greenplum 的确让人挺惊艳的,计算能力给习惯于 RDBMS 传统处理能力的 DBA 会留下很深刻的印象。有点一招鲜吃遍天的感觉。
Greenplum 还可以结合 Solaris 进行虚拟化 — Sun 任何时候都能搭配上自己的东西。
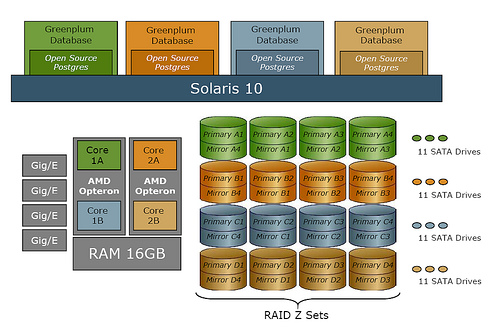
看上去都很美,问题就是海量数据每天怎么导入到 Greenplum 中来? 借助传统的 ETL 工具(Informatica / DataStage …) 或者自己写 ETL 功能脚本来做。这就是个麻烦事。海量数据的载入与导出,对于 Greenplum 来说,似乎只能用传统的老办法。如果 Greenplum 带一个 ETL 工具就真的强了。
在大哥大电话刚流行的年代,有个笑话说,发明家发明了一款超小超轻的手机,向另外一个人推销,价格还贼便宜。顾客买下刚要走,被发明家叫住:这里还有个大箱子是送给你的。这是什么? 这是这个手机的电池……
–EOF–
Greenplum 支持的这个 Bizgres 最近两年倒是好像停滞了。免费的午餐不是没有,但不会长久倒是真的。