按:此为客座博文系列。投稿人吴朱华,曾在IBM中国研究院从事与云计算相关的研究,现在则致力于研发下一代云计算系统,撰写一些与云计算相关的文章,他的个人站点: PeopleYun.com。(文章版权属于原作者,转载请勿混淆。本篇原文地址)
本篇是本系列最终章,将会首先总结了Force.com的设计理念,之后会对整个系列进行总结。
设计理念
根据 Craig Weissman 的演讲和几份官方的白皮书,在Force.com的设计方面Salesforce团队主要有下面这五大考量:
- 数据驱动:由于 Salesforce 主要面向企业用户,导致其上面运行的应用,无论是 CRM ,还是报表工具,都是以数据的CRUD(增删改查)为核心,所以 Force.com 需要由数据来驱动,而且也需要为此做一定程度的优化。
- 规模经济:由于需要在低价格和灵活付费的基础上提供可定制化应用,所以需要让尽可能多用户共享同一套系统,来大幅减低基础设施和管理等资源的投入,并实现规模经济的效益。
- 安全为先:由于在一套物理设备上将承载数以万计客户的企业级应用,那么如果出现严重的程序错误或者数据方面遗失或者错乱,将会发生非常严重的后果,所以安全问题是一个 Salesforce绝不能轻视的问题。
- 定制方便:虽然各个企业都会存在一部分比较通用的流程,但是每个企业都可能存在一部分私有或者独特的流程,所以Force.com需要提供方便的定制功能来帮助用户将更快捷地将企业的业务迁移到其上。
- 功能丰富:虽然用户能在 Force.com 上进行开发和定制,但是如果 Force.com 能提供更多的功能模块或者能让用户购买和整合第三方的应用将非常有效地帮助用户开发应用。
虽然这些设计理念说起来很容易,但是实现起来是非常艰难的。可贵地是,Salesforce 团队在开发 Force.com 的过程中基本实现了这些设计理念。
总结
关于本系列的总结,也主要包括五个方面:
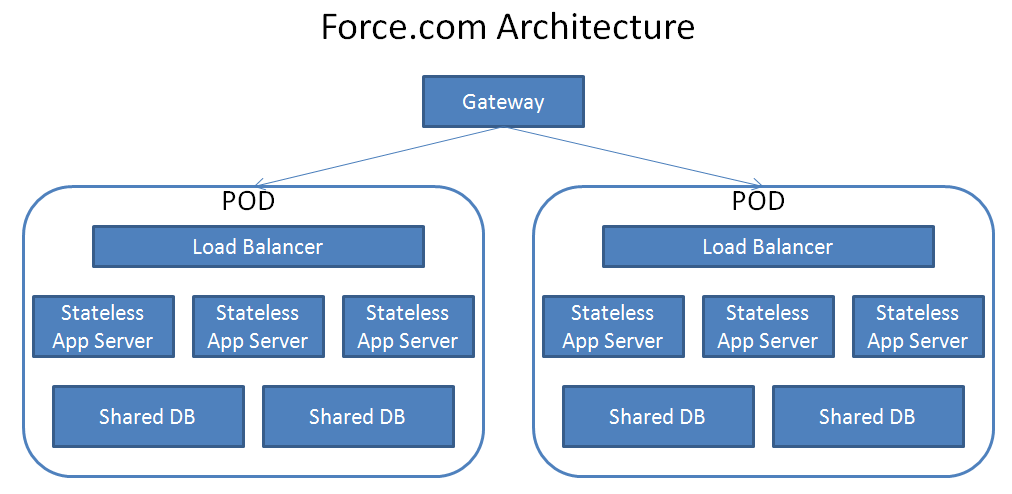
- Trade-Off 是难免的:为了满足设计目标,有时不得不做Trade-Off 。由于 Salesforce 所需要承载的多租户应用的规模之大,定制化需求之高都是前所未见的,所以Salesforce并没有采用在第二篇所提到几种常见模型,而是从长计议,采用了更灵活但技术要求更高的 Metadata 方式。 还有为了避免在数据库中执行成本非常高并会 Locking 整个数据库的 DDL(数据库定义语句)操作,所以在 Force.com 运行的时候是无法创建和修改数据库表,而这样将会提升实现的难度。
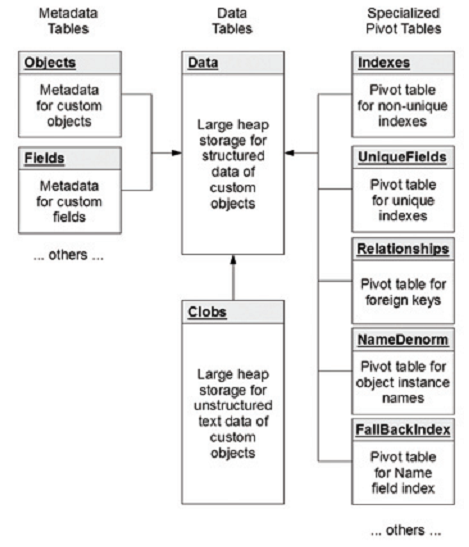
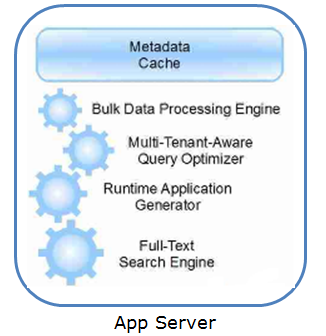
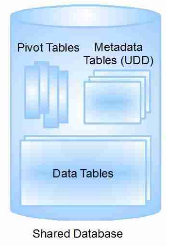
- 优化很重要,虽然 Force.com 的多租户架构就像 Java 一样,采用了很多动态生成的机制。很显然,如果像早期的Java那样缺乏优化的话,那么 Force.com 整体的性能将会非常糟糕,从而无法实现其设计要求。但幸运的是,Salesforce 团队不仅做了优化,而且凭借着其很多核心成员来自于 Oracle 的背景,在数据库端做了很多高水平的优化,比如添加了很多貌似累赘的 Pivot 表来加快部分常用数据的读取。
- 人才很重要:经过本系列的介绍,可以看出 Force.com 的整个架构并不全是在现有的框架和库的基础上构建的,而是为了设计目标开发了很多比较底层和比较复杂的模块,而且这些模块是只有那些顶级的程序员才能编写出来的,所以说如果没有硅谷那个庞大的优秀程序员池,Salesforce 就很难走到今天。
- 软件是一个进化的工程:刚开始的时候 Salesforce 架构是普普通通的 B/S 架构,但是随着用户不断地提出定制化的要求,Salesforce 也不得不在架构中引入多租户的概念,之后,由于用户需要更灵活的,可伸缩的和功能更强大的平台,导致 Salesforce 不断地对其架构进行重构,到最后,终于整出了 Force.com 这一优秀的 PaaS 平台。
- 有用的创新才珍贵:Salesforce 不仅在 Force.com 引入很多创新,而且都非常有效。在这些创新当中,最有用的除了 Metadata 驱动这种多租户架构实现机制之外,还有一个名为”回收站(Recycle Bin)”的概念,这个回收站主要存储30天来那些从数据表里面删除的数据,如果用户在30天内发现数据是误删,可以对数据进行恢复,这样既减低数据误删的可能性,而且能回收部分物理资源,比如硬盘空间等。
最后,我想说虽然到现在为止,Salesforce 还不能算是一场巨大的商业胜利,但是它在产品和思路方面有很多值得我们借鉴的地方,这也是我写本文的初衷,并谢谢大家花时间在这个系列上面,希望能对得起大家的时间。还有,如果大家对本系列有什么疑问或者见解,那么就不要吝惜你的时间,请留下你的评论。
本系列参考资料
- The Internal Design of Force.com’s Multi-Tenant Architecture
- Salesforce.com在Wikipedia上的介绍
- Cloud Computing in Practice:Fast Application Development and Delivery on Force.com
- The Force.com Multitenant Architecture
- Multitenancy在Wikipedia上的定义
- Salesforce多租户架构
- A Comparison of Flexible Schemas for Software as a Service
本系列文章列表
- 剖析Force.com的多租户架构(1)- Salesforce的简介
- 剖析Force.com的多租户架构(2)- 多租户的介绍
- 剖析Force.com的多租户架构(3)- Force.com的多租户架构(上)
- 剖析Force.com的多租户架构(4)- Force.com的多租户架构(下)
- 剖析Force.com的多租户架构(5)- 总结
–EOF–