按:此为客座博文系列。投稿人吴朱华,曾在IBM中国研究院从事与云计算相关的研究,现在则致力于研发下一代云计算系统,撰写一些与云计算相关的文章,他的个人站点: PeopleYun.com。(文章版权属于原作者,转载请勿混淆。本篇原文地址)
本篇是上篇的延续,主要是通过对上篇提到的几个模块进行深入地分析。
大规模数据处理引擎
由于Force.com需要处理的数据量不论是来自网页端,还是来自Web Service端都是非常巨大的,所以Salesforce在Force.com中引入了特制的大规模数据处理引擎来处理大量的数据读写和在线事务。它主要有两大特点:其一是对大规模数据处理进行了优化,特别是当一个API调用发来很多待处理的数据时,这个引擎能非常快速地处理。其二是这个引擎内置错误恢复机制,当处理大规模数据时候,假如其中一个步骤发生错误时,这个引擎会捕捉和修复这个错误,并且保持这个步骤之前正确的结果以避免整个重做。
多租户感知的查询优化引擎
大多数现在数据库都自带基于成本的查询优化器,这种优化器主要是基于数据库表和索引数据等相关数值来进行计算和比较。但是由于传统的基于成本的优化器都是主要为单租户的环境设计的,所以他们并不能很好地适应多租户的环境,因为在数据库中是没有多租户这个概念。为了让优化器能够在多租户环境下良好工作,Salesforce在Oracle自带优化器的基础上搭建了一个多租户感知的查询优化引擎,它也主要有两个特点:其一是这个引擎为每个多租户对象维护了一整套便于优化的数据(租户层的,组层的和用户层的)。其二是这个引擎也维护租户和租户下面用户的安全信息,这样不仅能提升了效率,因为能避免将那些不属于这个租户的数据加入到计算,而且能提升数据的安全性。
全文检索引擎
全文检索功能对Web应用而言,基本可以算是一种基本功能,而对基于Force.com的应用而言,同样如此,Force.com为此内置一个全文检索引擎,其是基于大名鼎鼎的Lucene技术。当一个运行在Force.com平台上的应用对数据库中数据进行更新的时候,会有一组称为检索服务器的后台进程来异步更新数据相关的索引。通过这种异步机制不仅能够保证检索工作不影响处理事务的效率,而且同时也能让用户使用到最新的搜索结果。为了优化这个检索流程,系统会同步将修改过的数据复制到一个内部”等待检索”的表,之后检索服务器会访问这个表来进行检索,这样好处是减少了检索服务器的I/O处理量。而且为了更好地适应多租户环境,检索引擎自动为每个租户维护一个独立的索引。
数据库表的设计
下图为Force.com的数据库表结构:
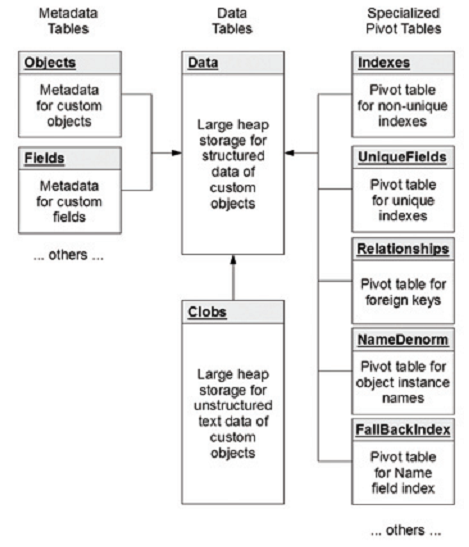
图1. 数据库表的结构(图源自参[4])
Metadata表
Metadata表的作用是存储用户定制的对象和对象所包含的字段的结构信息,不保存具体的数据,主要有两大类:
- Object Metadata表:这个表主要存储对象的信息,其中主要字段包括对象的ID(ObjID),拥有这个对象的租户的ID(OrgID)和这个对象的名字(ObjName)。
- Field Metadata表:这个表主要存储对象附带字段的信息,其中主要字段包括字段的ID(FieldID),拥有这个字段的租户的ID(OrgID),这个字段的名字(FieldName),这个字段的数据类型(datatype)和一个布尔字段(IsIndexed)来定义这个字段是否需要被检索。
Data表
Data表的作用和Metadata表正好相反,它主要存储那些用户定制的对象和对象所包含的字段的数据,主要也包括两大类:
- Data表:这个表放置着上面那些对象和字段所对应的数据,核心字段有全局唯一的ID(GUID),租户ID(OrgID),对象的ID(ObjID)和存放对象名字的”Nature Name(自然名称)”,比如这行和一个会计对象有关,这行的””Nature Name”字段可能是”Account Name”,除了这些核心字段之外,这个表还有名字从Value0到Value500的501个数据列来存储数据,而且这些列都是varchar的形式来承载不同类型的数据,这种数据列也被称为”flex列”。
- Clob表:这个表主要存放那些CLOB(Character Large Object,字符大对象)数据,对象最大支持到32000个字符。
Pivot表
Pivot表,也称为”数据透视表”,在Force.com中是以denormalized (去规范化)格式存储那些用于特殊目的的数据,比如用于检索(indexing),唯一性和关系等,主要作用是加速这些特殊数据的读取以提升系统整体的性能。主要有五种Pivot表:
- Index Pivot表:由于Data表里面数据都是以”flex列”的形式存储,所以很难在Data表的基础上对表中的数据进行检索,所以Force.com引入Index Pivot表来解决这个问题,系统在运行的时候会将需要索引的数据从Data表同步到Index Pivot表中相对应的字段来方便检索,比如这个数据的类型是日期型的,那么它将会被同步到Index Pivot表中的日期字段。
- UniqueFields Pivot表:这个表是用来帮助系统在Data表中字段实现唯一性。
- Relationships Pivot表:Force.com提供了”Relationship”这个数据类型来定义多个对象之间的关系,而Relationships Pivot表则起到方便和加速”Relationship”数据读取的作用。
- NameDenorm表:是一个简单的数据表用于存储对象的ID(ObjID)和这个对象的实例的名字,主要让一些仅需获取名字的查询调用,从而让一些简单的查询无需查询规模庞大的Data表。
- FallbackIndex表:这个表将记录所有对象的名字,来免去成本高昂的”UNION”操作,从而加速查询。
APEX
APEX的语言是为Force.com度身定做的一门语法上类似Java的强类型面向对象语言,主要可以通过APEX在Force.com上创建Web Service,编辑复杂的商业逻辑和整合多个Force.com的模块等。APEX主要以两种方式执行:其一是以单独脚本的形式,按照用户的需要执行。其二是以触发器的形式,当一个特定的数据处理事件发生的之前或者之后,与这个事件绑定的APEX代码将会被执行。而且所有APEX代码将会以Metadata的形式存储在Metadata表内。当一段APEX代码被调用的时候,APEX的翻译器(runtime interpreter)将会从Metadata Cache读取编译之后的APEX代码,而且能够同时被多个租户共享以提升效率。
那么为什么要在Force.com引入APEX这门新的语言,而不是像Google App Engine那样支持已经有一定市场占有率的语言,比如Java和Pyhon。Salesforce的首席架构师在谈到这点时,他提出了一个非常重要的原因,那就是安全,首先,Salesforce会APEX语言度身设计一组管理工具,通过这个工具能够非常方便地监控APEX脚本的执行,并且能知道这个脚本在执行过程所耗费的CPU时间,内存容量和SQL语句的数量等数据来判断是否需要中断这个APEX脚本,以避免影响到属于其他租户的应用,如果中断的话,系统会抛出一个runtime exception给上层的调用者。其次,基于APEX语言的代码能够对其内嵌的SOQL(Sforce Object Query Language)和SOSL(Sforce Object Search Language)进行验证来避免实际运行时出现错误。还有,在安全方面除了APEX自带的功能之外,Salesforce还要求每个上传到Force.com的APEX脚本,都需要自带能覆盖其75%代码的测试用例,这种做法不仅显著地提升APEX代码的质量从而确保平台整体运行的稳定,而且在Force.com自己更新的时候,能使用这些用例来确保新的更新不会影响现有的基于Force.com的应用。
关于Force.com多租户架构的详细介绍已经告一段落,下篇会对本系列所提到的内容进行总结!
本系列文章列表
- 剖析Force.com的多租户架构(1)- Salesforce的简介
- 剖析Force.com的多租户架构(2)- 多租户的介绍
- 剖析Force.com的多租户架构(3)- Force.com的多租户架构(上)
- 剖析Force.com的多租户架构(4)- Force.com的多租户架构(下)
- 剖析Force.com的多租户架构(5)- 总结
–EOF–
可以看出对于一个高度可扩展的应用,数据库设计不需要遵守那么多范式,在存储介质成本下降的今天,数据冗余既可以简化程序编写的复杂度,也能增加执行效率
数据冗余,应该未必增加执行效率,降低的可能倒是比较大。
只是在现有应用模式下,降低带来的潜在开销可以承受。
哦,我主要是被那么多的join给搞怕了,效率会降低是否指索引或者主外键的问题?
以前也作过类似的业务,对象表结构设计也与之类似,对于普通的用户请求没有问题,但是在对已有数据进行数据统计和相关报表的导出时,是一个很大的问题,即便使用专门的报表服务器来导出报表,也需要进行排队等候,不过Force.com的“flex列”还是很有意义的,它也可能是在兼顾我刚才说的那个问题,也就是架构师默认假设“flex列”的数目是少于500的。