这是去年发在《程序员》杂志的一篇文章。当时写得比较急,现在看起来,有些观点有些武断。仅供参考。
引言, “The one that is without any tradeoff is to have the logical storage master up in the cloud” by Bill Gates.
2008 年的 IT 界,云计算是个热词。很多企业都在宣称自己提供云计算服务,很多人也都在讨论云计算(一些明显是凑热闹的,比如所谓的”云安全”),从业界公认的几种云计算的服务能力看,都绕不开存储这个基础支撑组件,dSaaS(data-Storage-as-a-Service) 更是把存储提到了首要的位置。而从我们目前能得到的信息来看,在存储层已经解决很好的,恐怕也只有 Google 和 Amazon 两家,至于其他公司可能都还在路上,即使是微软,尽管也有自己的 Dryad ,但是实际上,仍然处于理论阶段,产品化的路还有点距离。

上面表格中的举例仅仅是为了举例,如果某家已经 “云计算了” 的公司大名不在上面,并非该公司”云”的不够彻底,应该只是笔者眼光差的原因而已。
越来越迫切的信息存储需求
根据 EMC 公司赞助 IDC 进行的研究计划 “Digital Universe” 的分析报告,在整个 2007 年,我们这个世界生成、占用的数字信息及复制总量大约是 281 Exabytes (1 Exabytes=1024 Petabytes ,1 Petabytes = 1024 TB 这里换算都按照二进制的换算),这个数据平摊到地球上的所有人,大约是每个人 45 GB的数据;截至到笔者写稿的时候,2008年到现在整个世界已经生成了大约 374 EB 的数据(可以到 “Digital Universe” 页面查看最新的数据,也可以下载一个评估工具,看看自己产生的数据是大约如何);到 2011 年,每年产生的数字信息大约是 1800 EB,10倍于2006 年产生的信息量。做为对比,Google 每天处理的数据大约是 20 PB 的样子,Google 的目标是要组织所有的信息,看来并非易事。
其他可参考数据:据美国国家档案馆工作人员估计,布什政府电子档案存储量大约为1亿GB,这一数字约为前总统克林顿两届政府档案总量的50倍,是国会图书馆2000万册编目图书内容总量的5倍。
每年激增如此庞大的信息量,加上已有的历史数据信息,对整个业界的数据存储、处理带来了很大的机遇与挑战。通过该研究能看出,在可用存储之间与信息生成总量之间不是严格匹配的,一方面多媒体领域信息增长过快,一方面因为不合理的存储分配、占用情形比比皆是。例如研究表明一封大约 1M 的邮件发出后,经过不同服务器的存储、备份、归档等最后总体占用空间竟然达到惊人的 50M 之多。正如云计算的初衷是为了充分发挥计算机闲置资源,提高总体使用率以便达到经济效益,云计算中的存储方面也应该能有效提高存储利用率而进一步创造价值,盲目的复制、堆积数据是没有出路的。工业界提倡节能减排,其实 IT 界应该提倡一下节约存储了。
什么是云存储 ?
其实,什么是云计算都很难有一个权威的定义,笔者在这里更愿意把”云计算中涉及的存储”简称为云存储(Cloud Storage)。云存储本身离不开云计算,更多的时候云存储是做为云计算的一个支撑组件。
云存储不是简单的在线存储或是网络硬盘,在线存储服务只是云存储能够提供的众多服务中的一种而已。
云存储的特点
云存储至少应该能够具备如下特点:
- 高可靠性
- 高可用性
- 低成本
- 高扩展性
- 自动容错能力
- 易管理性
- 去中心化
谈到存储,可靠性还是要排到第一位的。没有人喜欢买三天两头坏掉的硬盘,代表高科技形象的云存储可靠性也要加强。
如果云存储服务不是针对在线用户的,那么没有什么实际意义,如果针对在线用户,不具备足够高的可用性也是没有意义的。Amazon 的 S3 服务给足够多的 Web 2.0 企业解放了在硬件存储上的压力,但是偶然的一次宕机会影响所有的 Web 2.0 用户;
云存储本质上还是规模化经济。如果成本不能有效的控制,那么云存储对厂家、对用户来说是没有意义的;
云存储组件应该具有足够高的扩展性,应该能够通过在线扩充存储单元进行有效的平滑线性扩展;
因为低成本的,存储组件的损耗率应该很高,云存储厂商应该能在软件层做到自动容错而不是依赖硬件本身的容错;
构建云存储系统,可管理性应该在设计之初就要考虑到,如果管理太复杂,很难做到低成本,稳定性、可靠性也会受到挑战。
对元数据的管理不应该通过少数或者单一的管理节点来操作或者存储。
云存储的关键技术与服务形式
要建设成功的云存储系统,高扩展性、高可靠性的分布式文件系统是一个关键因素。而硬件问题反而是次要的。
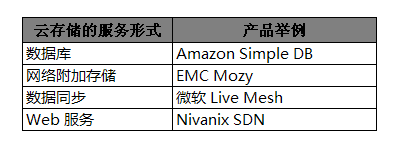
云存储的服务形式见上表。
未完待续…