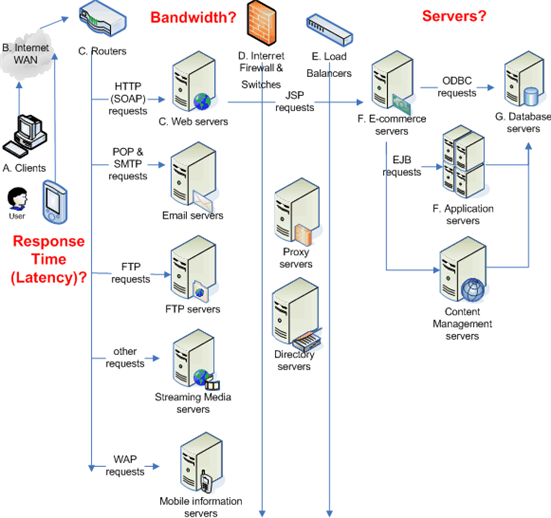
偶然看到以前写过的这篇帖子 『小规模低性能低流量网站设计原则』,重新发到微博上引起了一点反响,觉得有必要以 Linode VPS 为例再做个简单的优化实践说明,免得总有人问我,也顺便赚点点击量 :)
假定现在你已经有了一个基本的 VPS 可用,基本内存 512MB 。参考官方提供的各种安装指导将 LAMP 这个组合运行了起来,操作系统一般 Ubuntu ,Web 服务器 Apache ,数据库 MySQL ,然后是 PHP ,以及需要安装的应用软件,WordPress 、Drupal 或是 OpenCart 什么的,一步一步配置好,能够正常的浏览页面。按照官方指导文档操作的一个好处是会包括一些基本的优化一点的配置。不至于出现太大的错误。
一旦应用就绪后,登录到操作系统中,通过 top / iostat / free 等基本操作系统命令收集基准数据,做记录。收集信息越全面,对于后面的优化就越便利。优化没有魔法,只有合理的方法。
1.内存相关的调整
内部测试或是较小范围使用,可能这样也不会遇到太大问题。一旦访问人数多了一点,机器响应可能就有点慢了。对于 VPS ,第一步着手调整的就是各个组件对内存的使用。因为内存受限,对内存的使用一定要精打细算一点。记住一旦内存耗尽,一部分内存调用压到磁盘上,系统负载会飙升,一般就会挂掉。 一般来说,对于 LAMP 环境,以下几个地方要注意:
PHP 程序的内存相关的调整
PHP5 配置文件 php.ini 中 memory_limit 定义的值默认情况是16MB,该参数定义单个 PHP 脚本消耗最大的内存大小(大意)。如果程序某个页面需要的内存超过这个限制,访问者最可能遇到一个 HTTP 500 错误,查看 Web 服务器错误日志也可以看到。多数情况下,这个值需要做相应调整。比如设置为32MB,是否合适,需要做观察。有一个经验方法是观察 top 命令的输出,看相应进程的 SHR 字段的值,实际上总是尽量大一点点。但不能过大,一旦有个别程序写的不好调用的时候占用过多资源,会导致 VPS 挂掉。
经常有人问,这个服务器跑某某 Web 应用,能支持多少并发? 一个大致的思路是估算单个进程占用的内存,看系统能分配多少内存给应用程序,并发的量大致可以估算得到。但实际上,这个提问基本没多大价值。
另外,还有一个比较重要的参数需要修改 output_buffering 需要修改为 On 或是具体数值(eg, 4096)。修改配置后,检查是否生效(如何检查?)。另外,记住error_log的位置,随时查看。
MySQL 数据库内存占用
如果不确定 MySQL 内存使用情况,可以利用 MySQLReport 这个工具收集一下 MySQL 实例的信息报告,不同时间段多收集几次作为对比。然后相应的调整 key_buffer/query_cache_size 等参数的大小, 一次调整一个参数,重启动 MySQL ,继续抽取报告,分析数据,然后调整下一个参数。既然需要编辑配置文件 my.cnf , 建议顺手加大一点 max_connections 这个参数(为什么?)。
多数内存问题都是由数据库 I/O 引起,导致 I/O 问题多由不合理数据库调用有关(这么说严谨么?),解决不合理调用要么修改应用,要么通过查询缓存或是 Key-Value Cache 等办法缓解。这地方说来话长,假定 VPS 上基本不会有这么复杂的环境。
2. 影响 CPU 利用率的调整
这个主要针对 PHP 的 Opcode(Accelerator) 而言,解析、编译PHP代码是相当消耗CPU的操作。常见的要么是 APC, 要么是 eAccelerator 或是 XCache,在 Ubuntu 下安装配置都相对简单,参数调整简单搜索一下就知晓了。如果是 PHP 环境,那么一定要用 Opcode 减少 CPU 的负荷(为什么?)。至于用哪一个关系倒是不大,但前提是必须要有一个。
另外,张磊同学这篇 让进程运行在指定的CPU 对于特定需求的应用,很有借鉴意义。
3. 网络参数控制
修改 /etc/sysctl.conf 文件,增加如下几行:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
然后 sudo sysctl -p 使修改生效。使用如下一行命令观察半连接数量:
$ netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
其实一般来说,网络连接数不会成为最明显的瓶颈。但顺手调整一下也好,「不费电」。有人问,如果遇到 DDoS 怎么办?忍着。
4. 应用程序相关的调整
比较流行的开源程序,不安装第三方插件的情况下,性能多少过得去。建议如果没有必要,不要启用过多的第三方插件,尤其是一些带有统计或是「智能」显示内容之类的插件能不用就不用。
这些开源程序也基本上都有面向前端优化的静态化解决方案,比如 WordPress 的 Cache 相关的插件,强烈推荐启用。有时间看看前端优化的实践建议。
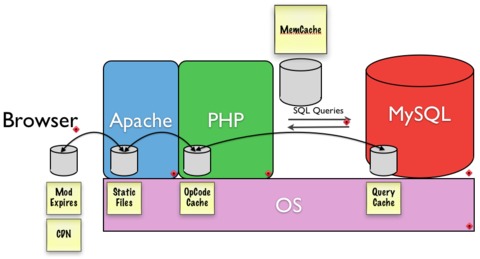 (图片来源)
(图片来源)
优化最重要的是找到瓶颈,对症下药。前面已经说到了内存、CPU、网络,大致提了一点 I/O 问题,基本也就够了。PHP 的 Log , MySQL 的慢查询 Log ,Apache 的 Error Log ,常过滤看一下有没有新情况。
补充一点,别忘了修改 OS 的 ulimit 限制:
编辑 /etc/security/limits.conf 增加如下两行(具体数值大点小点问题不大):
* soft nofile 40960
* hard nofile 40960
编辑 /etc/pam.d/common-session ,增加如下一行:
session required pam_limits.so
编辑 /etc/profile ,增加如下一行:
ulimit -SHn 40960
重新启动 OS 即可生效。
Linode 后台提供了几个基本的统计图,基本够用。可以设置磁盘 I/O 过高的时候报警,系统会发邮件给你。注意看一下网络流量的使用。不要因为个别文件被盗链而将带宽消耗殆尽。
上面提到的不少修改建议不要照葫芦画瓢,知其然,还要知其所以然。每一步的调整多阅读系统手册,尤其是涉及到具体的参数数值,一定要针对实际情况修改。对基本的配置足够掌握之后,可以根据具体情况尝试性能效率的组件,比如用 Nginx/Lighttpd 替换 Apache ,但是要记住,如果 Apache 不是瓶颈的话,用传说中性能更好的 Web 服务器来替换无疑是折腾。
再次提醒不要过度优化,足够满足需求就行了。有更多的精力完全可以放在其他环节上。另外,如果基本的调整做过之后,想用最省事的办法改善性能,那么,直接向服务商购买额外的内存吧。
好吧,最后我想说的是其实这个优化思路并不局限于 VPS ,这个最小实践套路对于复杂的服务器环境也是基本适用的。 –EOF–
Tip:页面不要引用太多的三方脚本。否则也会被拖慢不少。