用什么来衡量一天没有白过? 可能看到一篇好文章能算做一个条件。infoQ 上的这篇 Scalability Best Practices: Lessons from eBay 会让每个架构师都比较激动的。
过几天估计 infoQ 中文站就翻译这篇文章了,所以只记录一点自己的想法好了。在其中的 7 个实战经验中,每一条都值得写篇学习笔记,我比较关注面向 DB 的几条。
水平切分
对于 eBay 这样个头的大 Web 应用,如果数据不能分片,就无从谈及扩展。这个话题我之前描述过一点,文章中提及数据库层的切片要比应用层复杂许多,我想其中最大的一个难点就是不同用户之间的关联数据问题吧,否则就完全可以根据用户范围或者群体划分到不同的 DB 上。现实的应用总是如此复杂,让每个架构师都早生华发啊。
避免分布式事务
其中提到的前 Inktomi 工程师 Eric Brewer 提出的 CAP 定理: Consistency (C), Availability (A), Partition-tolerance (P) ,最多能同时选择两个。三个不能同时实现。对于 eBay ,选择的是 A 和 P,牺牲了一致性,而通过系统的其它手段(比如事件系统)来追回事务的完整程度。BTW: 这次倒是没有提及 BASE :)
虚拟化所有层次
这样做的目的是为了达到编程上的方便以及运营操作的灵活性。通过 eBay 的 O/R 层实现了对数据库的虚拟化。这样应用程序开发者无需关注数据存在哪里的。
Cache
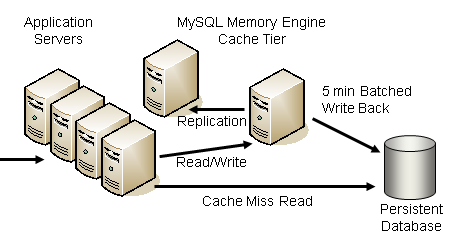
其中提到了 Cache 的应用场景:针对缓慢改变的数据、只读为主的数据、元数据、配置信息和静态数据等。 把握这个原则是很关键的。我个人就看到有病急乱投医的设计者把数据一股脑的扔进 Cache,潜在的麻烦很难消除。
强烈推荐大家直接点过去看一下该文。
补充:关于 BASE。
Basically Availble
Soft-state
Eventual Consistency

–EOF–