继续我的学习笔记之旅。Flickr 的 DBA Dathan Pattishall 在前几天的 MySQL 大会上分享了 Scaling Heavy Concurrent Writes In Real Time (Record every Referral for Flickr Realtime) ,其中介绍了 Flickr Stats 的设计经验。国内好多 Web 站点其实也在设计类似的功能,只是不知道细节罢了。
数据结构原型
字段 数据类型
Path_query Varchar(255) PK
Domain Varchar(50)
Owner Bigint
When Date
Object-ID Bigint
Object-Type Tinyint
Counts and stuff Various ints May be some keys
主键是字符串,开销太大。其他的索引如果做主键,也比较大。当表大小超过内存的时候,插入速度很慢,I/O 能力也上不来。
优化数据结构
数据预处理,通过 CONV(SUBSTR(MD5(Url),0,16),16,10) 把 Path_query 修改为 64 位的 ID (8字节), 主键为 ID+Owner+object+object-type,这个统计信息很容易抽象到一个数据对象,这个索引的设计也在于此。
另外补充一点,利用 PHP 的 ip2long() 和 long2ip() 函数对 IP 地址作预处理,耗费的存储空间只为原来地 25%,这是个很有趣的技巧。
数据 Sharding
对于海量的数据,以一个礼拜为间隔,水平分割。按照不同的数据力度每周一个表,每年一个全局表,再加上一个汇总表。数据量越大,InnoDB 存储引擎针对字符串的索引浪费的空间就越大。单个查询的 I/O 也自然大了起来。
所有应用对 DB 的响应要求 是 300 毫秒。但高并发写入的时候响应时间就糟糕起来。Flickr 的 Java 牛人实现了 Referral 队列,每 4000 条做批量处理。这样 IO 拥塞的就解决掉了。
总体的服务器规模过去 介绍过,对专业版用户的数据是永久保留的,而普通用户则只保留几周,为节省空间,采用 MyISAM 引擎,当用户转为专业版时,迁移数据。
补充一下,抓取 URL 是用的 curl 。最后,这篇 PPT 在线观看。
–EOF–
补充一张图:
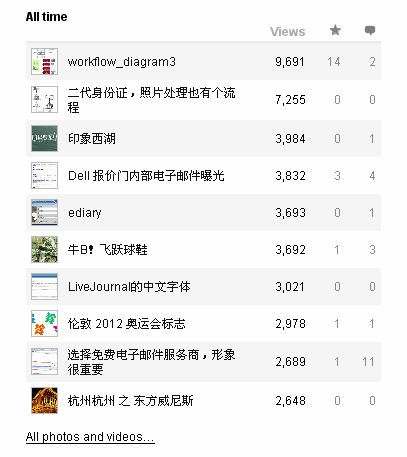
这是该功能的 UI 设计。
- 1) 请求触发统计。默认不激活统计。从而节省大量不必要的开销;
- 2) 统计,没必要过度设计;
- 3) 元素可点击
- 4) 设计洁癖