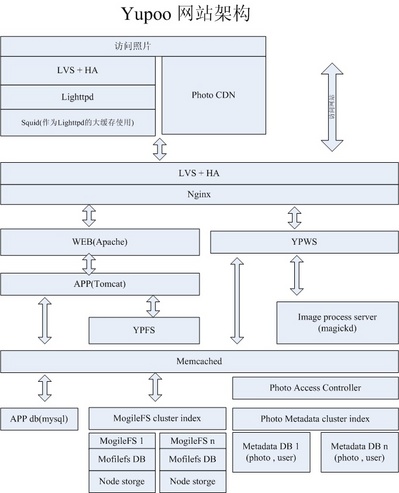
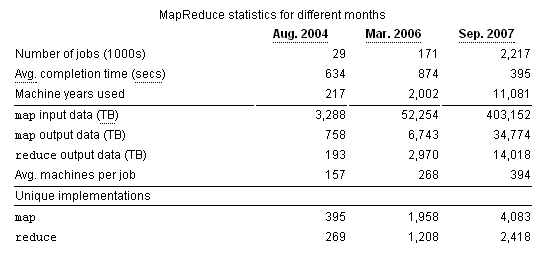
前年在帖子里介绍过 eBay 数据量超过 2PB,这么大的数据量管理和规划是需要一些艺术的,可惜网络上能得到的信息太少。最近又找到一篇关于 eBay 存储的介绍,这篇文章通过访问 William Crosby-Lundin (这位老兄现在已经跳槽到 SalesForce了)披露了一些数据,虽然该文距离现在有一年了,还是对我有不少参考价值。
eBay 存储团队当时 12 个人,管理 13 套存储,总容量 2PB 左右(不要刻舟求剑,现在超过 8 PB,2008-08-04) 了,8000 个左右光纤口,可用性 99.94%,工作量肯定不小。每周要起用 10TB 存储,这些存储有 75 个 LUN(也就说平均每个 LUN 135GB 左右,这个数据有些怪异)。连接到 SAN 环境的主机大约有 1000 台,数据库集群有 600 个左右,据我所知,这里的集群应该只是指 Data Guard。
这么多的数据库,I/O 开销肯定不小,如何消除存储热点呢? 该文只是笼统的说通过存储层与主机层的数据分片达到的。如果应用上 I/O 均衡做的好一些,可能存储热点问题不会成为瓶颈。
这个存储环境的部署应该有好几年了。所以最近一两年比较火爆的存储虚拟化与 Provisioning 技术都没有大规模起用。个人觉得 eBay 这么大的数据量, Provisioning 技术对于 eBay 的环境会是比较适合的。
有的时候,盲人摸象也是一种乐趣呀。
补充一下,超过 140 套集群。另外,提醒一下,这些数据是随着时间而变化的。切莫刻舟求剑。
–EOF–
Refer :
Our systems process in excess of 20 billion newly added records per day, 40TB being added every 24h, serving thousands of users and delivering hundreds of millions of queries per month in a true global 24×7 operation with distributed teams around the globe on systems over 8 PB in size (largest cluster >3PB), processing more than 30 PB of data per day.