前几天 Firefox 升级到 3.5.7 之后频繁崩溃,导致我也很崩溃。说也奇怪,Firefox 这个版本据说主要是解决以前版本的稳定性问题,还说要修复 Top crash 呢,可没想到在我的机器上反而更加的不稳定。开始猜测是一些扩展(Extension)升级带来的问题,把所有的扩展禁止掉,仍然 Crash。另外怪的是,即使使用的时候没问题,一旦退出 Firefox 的时候还是会提示软件有问题而崩溃。那个提交 Crash 报告的界面都快让我条件反射了。
因为 Firefox 是日常工作首选的浏览器,加上翻墙越脊的也很顺手,还不能弃之不用。昨天痛定思痛,决定仔细分析一下到底怎么回事。说也惭愧,尽管是 Firefox 的老用户,倒是没注意到 Firefox 对于 Crash 的反馈处理还是有一套比较不错的机制的。通过 Firefox Crash Reporter ,用户能够比较快速的定位到自己的问题。
提交了崩溃报告之后,在浏览器地址栏输入:
about:crashes
然后点击所提交的 Report ID,经过联机分析之后,会给出很有价值的提示。可以对比多组结果,便于最后确认。查看Crash Report,我的浏览器的两个主要问题是:
- 501429 NEW Gmail tab crash while closing it’s tab (caused by Google Talk Plugin)
- 531551 NEW Firefox 3.6 topcrash due to old Acrobat Plugin (nppdf32.dll)
问题和插件(Plugin)有关系,和扩展倒是关系不大。罪魁祸首一个是 Google Talk Plugin ,一个是 Acrobat Plugin,通过 Tools–>Add-ons–>Plugins 将这两个插件关闭。重启动 Firefox ,观察,问题不再复现,泪奔。
尽管不是扩展问题,但还是仔细看了一遍可能会带来问题的 Problematic extensions 列表,看完之后,把 IE Tab 换成了 IE Tab lite。
几点感慨:
- 对于客户端工具,如果追求扩展能力与第三方开发友好性,那么必然损失稳定性。而这个稳定性的损失如果不被用户理解,对产品的推广是比较危险的。
- 国内火狐团队在做什么? 至少作为用户,不知道,也打算用”针对国内用户定制”的产品。
- 其实很多时候解决办法就在那里,只是我们视而不见。
–EOF–
今天已经将 Firefox 升级到 3.6 了,目前稳定性尚可。
有来自火狐中国的朋友留言到”在将来版本的火狐中,整个插件体系被重新设计,所有的插件会在单独的进程中执行,不会影响到Firefox的执行”。这是一个好消息。
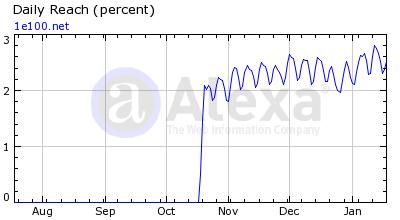
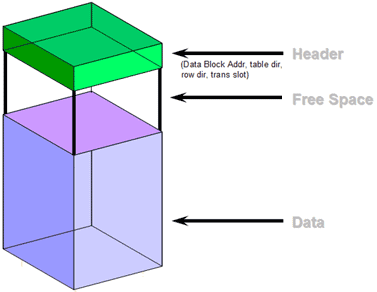 我们知道 Oracle 数据库引擎默认是以数据块(block)为存储单位,以数据行(row)作为存储与组织方式,当然理想情况是在一个数据块内存储更多的数据行,而实际上这样的方式对于一些列数较多的表不可避免的会带来存储空间的浪费。相反,以列(columnar)的方式组织、存储数据在空间上会带来很好的收益,但是对于依赖于行的查询,也是我们最常用的查询方式,则性能会差很多,而对于数据分析方面常见的汇总之类的查询,因为只需要扫描较少的数据块,就会达到很好的性能。可实际环境中,人们往往要熊掌与鱼兼得,为了达到空间和性能上的折衷,Oracle 引入了新的方式:用行与列混合的方式来存储数据。
我们知道 Oracle 数据库引擎默认是以数据块(block)为存储单位,以数据行(row)作为存储与组织方式,当然理想情况是在一个数据块内存储更多的数据行,而实际上这样的方式对于一些列数较多的表不可避免的会带来存储空间的浪费。相反,以列(columnar)的方式组织、存储数据在空间上会带来很好的收益,但是对于依赖于行的查询,也是我们最常用的查询方式,则性能会差很多,而对于数据分析方面常见的汇总之类的查询,因为只需要扫描较少的数据块,就会达到很好的性能。可实际环境中,人们往往要熊掌与鱼兼得,为了达到空间和性能上的折衷,Oracle 引入了新的方式:用行与列混合的方式来存储数据。