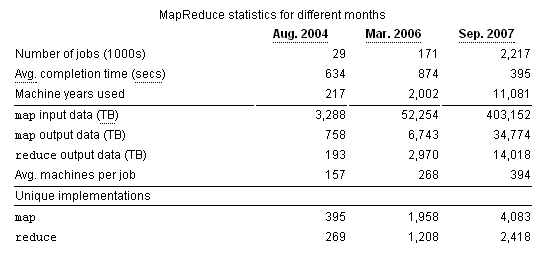
从 Greg Linden 的文章看到的数据:Google 的 MapReduce 平均每天处理 20 Petabytes 的数据。每天能跑完 10 万个工作任务。光是 07 年 9 月,就用掉了 11081 个”机器年” ,跑了 220 万个 Mapreduce 任务。这个计算能力是惊人的。
Yahoo! 也用 Hadoop 实现了 Mapreduce , 我个人感觉和 Google 可能还有一段距离。光有计算环境还不行,还要有应用程序来实现功能,Google 已经实现了超过 1 万个应用程序,Yahoo! 有多少呢?
这方面估计微软更没戏了,要是弄个不包括 “Window” 的 Windows 服务器集群估计还能差不多,否则,光是一个视窗要耗费多少计算资源? 如果服务器规模是几万、几十万台,计算能力的浪费是惊人的。微软的对抗计划是 Dryad.
所以说啊,Google 的计算能力仍是独步武林,虽然有不服气的,但有什么办法? 这方面 Google 就是强啊
–EOF–
补充:
更多的数据(来源):