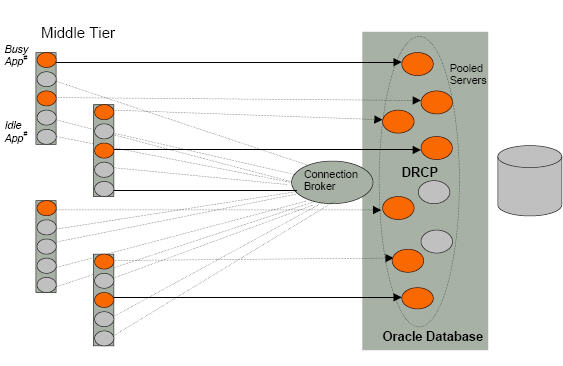
Oracle 对 PHP 的支持一直是不错的(只是国内好像 PHP + Oracle 的开发并不多)。 Oracle 11g 中的新特性数据库驻留连接池(Database Resident Connection Pool,DRCP) 对 PHP 应用进一步扩展带来了一种可能。
这个特性应该重点针对 PHP 应用的。PHP 不支持真正的多线程,非持久连接非常消耗 CPU 资源,扩展性也差;持久连接扩展性好了一点,但是又额外占用更多的内存资源(PHP 之父在几年前的一个 Step-by-Step 优化演示的文章中很形象的说明了连接开销对应用的影响)。DRCP 的出现能更好的缓解上述两个问题,其共享连接能跨 Apache 与中间件节点,但共享的连接是基于数据库用户的,比如 Scott 用户登录到 DB 上的所有连接间共享。
Oracle 官方披露的测试数据是,在 4 CPU Intel Xeon MP 2.80GHz 机器上,2GB RAM, 32bit RHEL 4. 支撑到 14000 个链接的时候,CPU 使用率在 65% 左右。这个…还是太惊人了,根据我找到的另外一份测试结果,看来要大打折扣才能有参考性。
–EOF–
