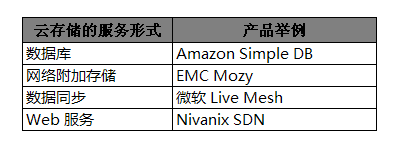
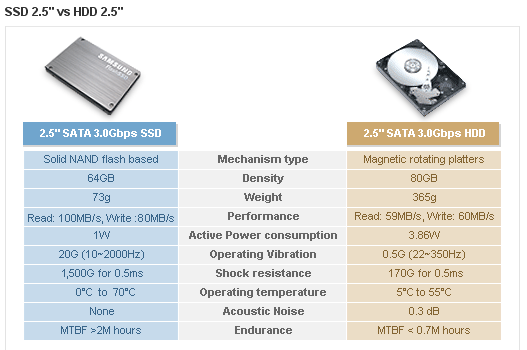
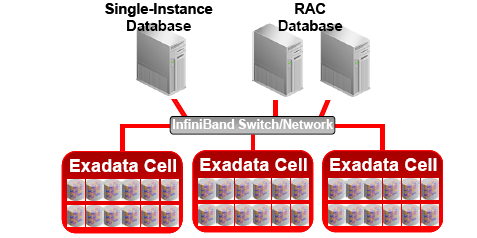
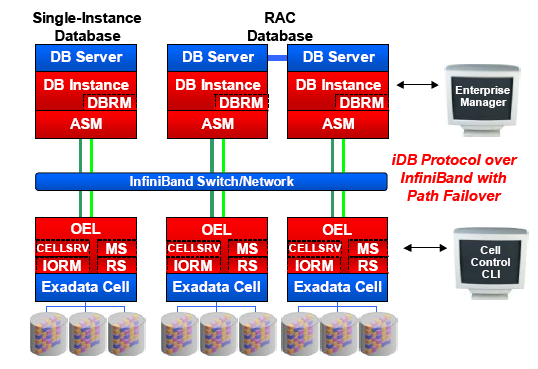
接上一篇。这其实是一篇综述文章 :)
是否该建设云存储服务?
可能有些企业已经在战略中加上了云计算这个关键字,问题是,真的需要那么多云计算么? 如果在技术上、规模化不能有效的节约成本,那么跟风建设云存储服务是缘木求鱼。更多的企业是自身的存储建设都远远不到位,大谈云存储无疑是痴人说梦。至少在国内,我们的基础建设还和国外有一段距离,而内容审查与一些政策上的限制又会增加建设、运营成本。
是否该使用云存储服务?
回答这个问题之前,我建议先看看服务提供方是否真的是云存储服务,如果只是炒炒概念,用老的架构支撑,换汤不换药,那还是谨慎为妙。企业如果不能从技术上做些本质突破而节约成本,那么成本肯定要转嫁到消费者身上,如果消费者不买单,那该服务如何能长久? 和我们现实生活中很多山寨 IDC 类比一下就知道了,动辄听到某主机托管商一夜之间蒸发,用户欲哭无泪的事情。
如果使用云存储服务,不妨和竞争对手使用同一家服务商。出问题的时候大家都出问题,保证始终处于同一起跑线。
在国内,短期内还看不到有规模的云存储服务商。由于网络的问题,企业用户也不太可能去使用国外的服务(不排除将来 Amazon S3 这样的服务能在国内提供服务)。期待在未来的一段时间能看到一些变化,但这恐怕只是乐观的想法。
云存储的潜在问题
- 数据安全
- 网络带宽问题
- SLA 的问题
同样是数据存储到云存储服务商那里,如果我的隐私数据被泄露了怎么办? 业务数据被竞争对手盗用了怎么办? 消除用户的顾虑仍然需要时间。
只有数据没有网络,好比鱼儿没有水。如何保证大规模数据的有效分发与负载均衡,这也是云计算提供方与使用方都需要考虑的问题。
对于提供云计算存储服务的公司,用户很难看到他们严格执行SLA (Service level agreement) 。遇到大规模故障的时候,还做不到有效的为所有用户提供服务支持的能力。
云存储的钱途与前途
时值全球经济的寒冬,能够为用户省钱的服务相信也应该能够赚到钱。从用户的角度上看,云存储解放了自身的生产力,能够允许中小创业团队集中精力做发展业务,只要不形成恶性竞争,应该不用担心盈利的问题。
就以 Amazon的 S3 来说,基本上也很好的展示并实践了 Web 2.0 长尾理论:利用企业建设剩余的存储以及网络带宽能力而为广大中小网站提供服务,前途大好。相信 Google 推出类似服务也是指日可待的事情。但这个市场内应该不会出现过多的有力竞争者,有些存储厂商(比如 EMC) 也在进入这个领域,数据存储不是问题,但网络能力可不是那么好解决的事情。
云存储与传统存储:SAN 能否还能发挥余热?
从我们前面提到的云计算中的存储特点来看,SAN(存储区域网络)产品就暴露出一些不适合的应用场景,毕竟 SAN 是面向集中式计算的架构。另外,大家也都知道 SAN 产品一般不便宜(现在也有厂商在力推低端海量存储产品,后面会介绍),而且,主机端如果用 HBA 卡,也会进一步提高成本;SAN 面向传统企业应用而设计的扩展能力难以满足云计算的需求。
目前尽管已经有一些企业在做集群存储然后打包出售,但相对还是在起步阶段。至少现在还看不到真正集群 SAN 产品的出现。当然,如果对云计算的存储部分不计成本的话,SAN 仍然可以在云计算中发挥一些作用,这倒是中了存储厂商的下怀。
不管怎么说,RAID 这个 SAN 中的概念在云存储中已经绝对不适合了。
集群 NAS 是否真的有机会 ?
有业界评论说集群 NAS 可能会演变成云存储的通用架构,我怀疑这是不是 Sun 公司的宣传手段,因为这事实上宣布了 ZFS 将是云存储中的一个关键点。
从现有的情形看,或许会有越来越多的在线存储服务拥抱集群 NAS 。但这不代表集群 NAS 前途光明能够在云存储大展拳脚。集群 NAS 最大的问题是海量数据的寻址是个麻烦事儿,然后是扩展性与容错性的问题,底层的容错性如果通过硬件来做,那么成本无疑会上升,这恐怕是企业不愿意接受的。
分布式文件系统
在开源领域,以 MogileFS 为代表的分布式文件系统能够用于一些相对规模较小的分布式存储场景,很多 Web 2.0 自己的分布式存储就是借鉴 MogileFS 搭建的,不过毕竟 MofileFS 的Meta 信息仍是集中存储、管理的,在更大规模恐怕有些吃力。
此外,Kosmosfs(http://kosmosfs.sourceforge.net/)、Lustre(http://www.lustre.org) 等也都在不断发展中,相信能够给有兴趣研究云存储的技术人员一些借鉴。也有一些软件厂商将其专有的分布式文件系统和存储打包在一起销售,而存储厂商也有的在结合自己的存储产品做一些尝试。目前还很少有相对成熟度的东西进入用户视野。
更多分布式文件系统列表参见维基百科的文件系统列表介绍。
分布式文件系统举例:拥抱开源 Hadoop 的 HDFS
尽管我们接触不到 Google 大名鼎鼎的 GFS (Google File System),但我们能免费获取 Hadoop 的 HDFS (Hadoop Distributed File System)。HDFS 相对上述的 ZFS 来说,属于专门针对廉价硬件设计的分布式文件系统,在软件层内置数据容错能力。Hadoop 目前的案例多数用在数据分析与并行计算上,倒是很少看到有支撑给互联网应用的数据服务,但相信随着其在开放环境中的快速成长, Hadoop 将不断壮大。
(HDFS 架构示意图. from: http://hadoop.apache.org/core/docs/current/hdfs_design.html 关于 Hadoop 也请参阅《程序员》杂志 2008年10月刊的文章。)
速成版存储方案成本评估
云计算中存储的起步容量,我们不妨按照 1PB 可用空间来准备。近年来,随着磁介质存储能力的提升,企业存储的价格也是一降再降,$2.00/GB 的底线早已突破,现在Sun 的Thumper 声称可以达到 $1.20/GB 的成本。(注:企业存储[不是个人消费品]的磁盘价格一降再降,而且有很重要的商业因素,具体的成本应该还要更低一些,只是不知道哪位朋友有更为准确的数字)
粗略估算一下,2PB 的原始容量成本大约是 250 万美元左右(List Price)。单位机柜空间密度最高的已经能够做到4U的机存储48TB的原始容量(目前能看到密度最高的了),这样最小只需要大约 45 个 4U 的机柜空间。其他方面,加上本地的工业电力价格,大致的硬件总体开销还是可估量的。软件方面,这个存储本身是基于 Sun 的 ZFS,内置的操作系统,成本也是可以控制的。
山寨云存储方案设想
在山寨精神盛行的今天,没准儿已经有人在搭建一套山寨版的云存储方案呢。比如目标定在 1PB 可用容量,预计至少需要如下的东西:
选择廉价的刀片服务器(自己”生产”就不必了),内置足够多的大硬盘,硬盘速度无所谓,预计每台机器预装4T容量(1T*4,坏了就整台机器替换),大约需要 500台服务器,总容量2PB,确保每一份数据都至少冗余在另外的物理机器上,冗余后,起码能得到1PB容量(如果备份的数据启用压缩,没准儿能提供更多空间呢)。机架物理空间怕是需要 1000 U多一些,每个标准机柜是42U,怎么也要准备 25 个机架吧,再加上网络交换机什么的… 然后是电力与空调散热问题。
再弄一套 Hadoop ,定制一下跑起来 …当然,山寨与否,关键是拼技术团队,一味的拿来主义注定只能跟风。
其实,这篇文章也是一篇山寨文。
–EOF–