按:此为客座博文系列。投稿人吴朱华曾在IBM中国研究院从事与云计算相关的研究,现在正致力于研究云计算技术。
本篇会首先会从程序员角度来介绍一下Datastore在使用方面的一些信息,之后会接着介绍Datastore是如何构建的。
使用方面
首先,在编程方面,Datastore是基于”Entity(实体)”这个概念,而且Entity和”对象”这个概念比较类似,同时Entity可以包括多个Property(属性),Property的类别有整数,浮点和字符串等,比如,可以设计一个名为”Person”的Entity,它包含名为”Name”的字符串Property和名为”Age”的整数Property。由于Datastore是”Schema-less”的,所以数据的Schema都由应用维护,而且能非常方便地对一个Entity所包含的属性进行增删和修改。在存储方面,一个Entity的实例可以被认为是一个普通的”Row(行)”,而包含所有这种Entity的实例的Table被称为Kind,比如,所有通过”Person”这个Entity生成实例,比如小吴,小朱和小华等,它们都会存放在同一个名为”Person”的Kind中。在结构方面,虽然也能通过特定的方式在Datastore中实现关系型结构,但是Datastore在设计上是为层次(Hierarchical)性结构”度身定做”的,有Root Entity和Child Entity之分,比如,可以把”Person”作为Root Entity(父实体),”Address”作为”Person”的Child Entity,两者合在一起可以称为一个”Entity Group”。这样做的好处是能将这两个实体集中一个BigTable本地分区中,而且能对这两个实体进行本地事务。
接下来,将谈一下Datastore支持那些高级功能:其一是提供名为GQL(Google Query Language)的查询语言,GQL是SQL的一个非常小的子集,包括对”>”,”<“和”=”等操作符。其二是App Engine会根据代码中查询语句来自动生成相应Index,但不支持对Composite Index生成。其三是虽然由于Datastore分布式的设计,所以在速度方面和传统的关系型数据库相比一定的差距,但是Google的架构师保证大部分对Datastore的操作能在200ms之内完成,同时也得益于它的分布式设计,使得它在扩展性方面特别出色。其四是Datastore也支持在实体之间创建关系,比如在Python版App Engine中可以使用ReferenceProperty在实体间构建一对多和多对多的关系。
下表为Datastore和传统的关系型数据库之间的比较:
| Datastore | 关系型数据库 | |
| SQL支持 | 只支持一些基本的查询 | 全部支持 |
| 主要结构 | 层次(Hierarchical) | 关系 |
| Index | 部分可自动创建 | 手动创建 |
| 事务 | 只支持在一个Entity Group内执行 | 支持 |
| 平均执行速度(ms) | 低于200 | 低于100 |
| 扩展型 | 非常好 | 很困难,而且需要进行大量的修改 |
表1. Datastore和关系型数据库之间的比较
最后,在接口方面,Python版提供一套私有的API和框架,在基本功能方面,比较容易学习,但在部分高级功能方面,比如关系和事务等方面,学习难度很高;Java版的API是基于JDO和JPA这两套官方的ORM标准,但是和现在事实的标准Hibernate有一定的差异。
实现方面
在实现方面,Datastore是在BigTable的基础上构建的,所以本段会首先重新介绍一下BigTable,之后会介绍Datastore的两个组成部分:Entities Table和Index,最后会讲一下它在事务和备份这两方面所采用的机制。
BigTable
在本系列的第一篇已经按照Google的Paper对BigTable技术做了一定的介绍,但其实BigTable本身其实没有之前介绍的那样复杂,其实就是一个非常巨大的Table,这也是是它之所以名为”BigTable”的原因,而且结构就像图1那样非常简单,就是一个个ROW,每个ROW都有一个Name和一组Cloumn,但是为了支持海量的数据,它将这个大的Table进行分片(Sharding)处理,每台服务器存储一个海量的Table的一小部分,并且为了查询效率,会对这个Table进行排序。就像App Engine的创始人之一Ryan Barrett所说的那样”BigTable is a sharded, sorted array “。

图1. BigTable简化版模型
在功能方面,首先,BigTable支持基本的CRUD操作,也就是增加(Create),查询(Read),更新(Update)和删除(Delete)。其次支持对Single-Row的事务与基于前缀和范围的扫描。
Entities Table
它是Datastore最核心的Table,是以BigTable的形式存在的,主要用于存储所有的Entity,而且是格式非常简单,每行都会有一个Row Name,也称为Entity Key(可认为它是一个Entity的Primary Key),而且只有唯一一个Column,主要用于存放被序列化的Entity。每个Entity的Key的生成是基于它的父Entity(如果有的话)和其父至上的Entity,直到其Root Entity。以下图为例,timmy的父Entity是jane,jane的父Entity兼Root Entity是Ethel,所以最后timmy的Entity Key是”/Grandparent:Ethel/Parent:Jane/Child:Timmy”。

图2. Entity Key的例子
Index
Index主要是为方便和加速查询而生的,所以在切入Index之前,先介绍一下Datastore主要支持那些查询,主要有三类:其一是基于Kind的,其二是基于Property值的,其三是基于多个Property值的。
Index表也是以BigTable的形式存在,但是和上面的Entities Table是分离的,主要用来单独存放那些需要被Index的数据,而且由于怕Index表体积太大,所以不会有时将其放置在内存中以提升查询速度。
主要有下面这几种Index表:
- Kind Index:用于加速那些用于获取所有属于某个Kind的Entity的查询,比如把所有属于Person这个Kind的Entity,包括小吴,小朱和小华等提取出来,Kind Index表每行有Kind和Entity Key这两个列,此Index会有系统自动生成。
- Single-property Index:用于加速那些基于单一属性值的查询,比如要找出所有Age在20之下的Person,Age就是所谓的那个单一属性值,Single-property Index表每行除了Kind和Entity Key之外,还有属性名和属性值这两个列,此Index也会有系统自动生成,还会根据升降序的不同,生成两个表。
- Composite Index:用于加速那些基于对多个属性值的查询,Composite Index表基本和上面的Single-property Index表非常类似,但是每行包括多个属性名和属性值,而且由于此Index消耗资源非常多,所有由开发人自己确定是不是需要这个Index,系统不自动生成。
事务
原则上所有对单一Entity的Write操作都是事务的,并基于上面提到的BigTable的Single-Row事务和Optimistic Concurrency Control这两个技术,下面是流程:首先,系统会读这个Entity的Committed Timestamp(提交时间戳),Write会以串行(Serialized)的形式写入到BigTable的日志中,之后,系统会将日志更新到BigTable的表中,如果成功的话,系统会更新这个Entity的Committed Timestamp,但如果系统发现在更新之前,Committed Timestamp发生了变化,也就是说另一个事务在这个事务执行过程中已经对这个Entity进行了操作,在这个时候,系统会重新执行这个事务。由于在整个事务过程采用Optimistic Concurrency Control,而不是Locking,所以在吞吐量方面表现不错。
如果要对多个Entity执行事务,那就需要将这几个Entity设为一个Entity Group,也就意味着将这几个Entity放在同一台物理机上。在执行的时候,会将以Root Entity的Committed Timestamp为准来对所有参与事务的Entity进行和上面差不多的事务操作。
备份
与BigTable基于Row级别的备份不同的是,Datastore是基于Enity Group级别,而且采用Paxos算法,所以Datastore的备份方法比BigTable的更安全。
总体而言,Datastore在设计理念上和传统的关系型数据库有很大的不同,所以其在反应速度和写数据方面不是最优的,但是现在Web应用以读为主,而且需要能通过简单的扩展就能支持其海量的数据,而这两点却是Datastore所擅长,所以Datastore非常适合支撑Web应用。
本篇结束,下篇是本系列的总结。
–EOF–
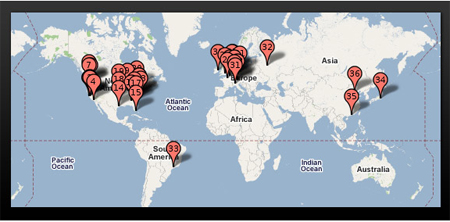 图1. 2008年Google全球数据中心分布图
图1. 2008年Google全球数据中心分布图