在西雅图扩展性的技术研讨会上,YouTube 的 Cuong Do 做了关于 YouTube Scalability 的报告。视频内容在 Google Video 上有(地址),可惜国内用户看不到。
Kyle Cordes 对这个视频中的内容做了介绍。里面有不少技术性的内容。值得分享一下。(Kyle Cordes 的介绍是本文的主要来源)
简单的说 YouTube 的数据流量, “一天的YouTube流量相当于发送750亿封电子邮件.”, 2006 年中就有消息说每日 PV 超过 1 亿,现在? 更夸张了,”每天有10亿次下载以及6,5000次上传”, 真假姑且不论, 的确是超乎寻常的海量. 国内的互联网应用,但从数据量来看,怕是只有 51.com 有这个规模. 但技术上和 YouTube 就没法子比了.
Web 服务器
YouTube 出于开发速度的考虑,大部分代码都是 Python 开发的。Web 服务器有部分是 Apache, 用 FastCGI 模式。对于视频内容则用 Lighttpd 。据我所知,MySpace 也有部分服务器用 Lighttpd ,但量不大。YouTube 是 Lighttpd 最成功的案例。(国内用 Lighttpd 站点不多,豆瓣用的比较舒服。by Fenng)
视频
视频的缩略图(Thumbnails)给服务器带来了很大的挑战。每个视频平均有4个缩略图,而每个 Web 页面上更是有多个,每秒钟因为这个带来的磁盘 IO 请求太大。YouTube 技术人员启用了单独的服务器群组来承担这个压力,并且针对 Cache 和 OS 做了部分优化。另一方面,缩略图请求的压力导致 Lighttpd 性能下降。通过 Hack Lighttpd 增加更多的 worker 线程很大程度解决了问题。而最新的解决方案是起用了 Google 的 BigTable, 这下子从性能、容错、缓存上都有更好表现。看人家这收购的,好钢用在了刀刃上。
出于冗余的考虑,每个视频文件放在一组迷你 Cluster 上,所谓 “迷你 Cluster” 就是一组具有相同内容的服务器。最火的视频放在 CDN 上,这样自己的服务器只需要承担一些”漏网”的随即访问即可。YouTube 使用简单、廉价、通用的硬件,这一点和 Google 风格倒是一致。至于维护手段,也都是常见的工具,如 rsync, SSH 等,只不过人家更手熟罢了。
数据库
YouTube 用 MySQL 存储元数据–用户信息、视频信息什么的。数据库服务器曾经一度遇到 SWAP 颠簸的问题,解决办法是删掉了 SWAP 分区! 管用。
最初的 DB 只有 10 块硬盘,RAID 10 ,后来追加了一组 RAID 1。够省的。这一波 Web 2.0 公司很少有用 Oracle 的(我知道的只有 Bebo,参见这里). 在扩展性方面,路线也是和其他站点类似,复制,分散 IO。最终的解决之道是”分区”,这个不是数据库层面的表分区,而是业务层面的分区(在用户名字或者 ID 上做文章,应用程序控制查找机制)
YouTube 也用 Memcached.
很想了解一下国内 Web 2.0 网站的数据信息,有谁可以提供一点 ?
–EOF–
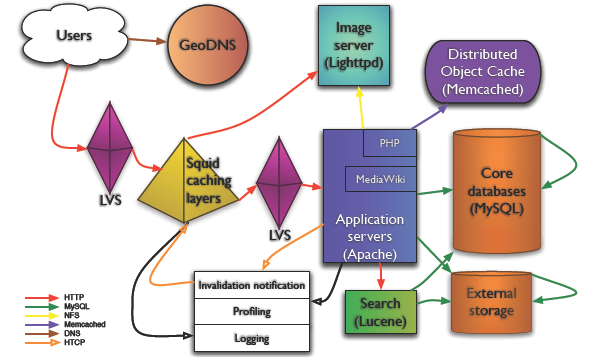 Copy @Mark Bergsma
Copy @Mark Bergsma{kind=link}