今天参加了 EMC 组织的存储技术培训。因为频繁被电话打扰,导致听课效果并不是那么好。很多内容似曾相识,只是都断断续续的,几乎每次培训都是这样的,总有”断点”。
上午是 CLARiiON 的简单介绍,在模拟操作的时候我发现了以前漏掉的一个盲点:Binding LUN 的时候,那个 Alignment Offset 的选项到底是干啥的? 讲师简单说了一下,感觉不太对路子。刚才闲下来,查找了一下这个信息,大致搞明白了这个 ”Alignment offset“。
用 ”Alignment offset EMC“ 作关键字搜索到的第一篇文档是 Dell 工程师写的。这里面用了一个词 “signature block” , 莫名的一个词,我相信是 Dell 工程师自己发明的(用 Metadata 不就得了)。另外两个关键词是 “Windows” 和 “31.5KB” ,为啥是 31.5KB ,不知道。接下来在 EMC 的 Powerlink 网站上找到了比较详细的说明。
首先确定一下,这个问题更多是影响 Windows 系统。
老的 BIOS 代码,使用 ”柱面、磁头、扇区数“这一套机制而不是 LBA (Logical block addressing )的模式来寻址。Linux 的 fdisk 工具还是 Windows 磁盘管理器,在每个格式化的设备上都放置一份 MBR 。这个 MBR 占用 63 个隐含扇区 (63*512=31.5KB, Bingo!)。这个问题在 Windows 上存在,在 VMware 上也存在,offset 同样是 63。 在有些 Linux 上,因为 Boot Loader 的不同,也会有类似的问题。
无视 Alignment offset 会导致的问题:
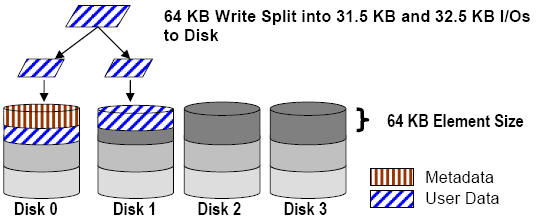
如图所示,一个 IO 会分裂到两个 Disk(Device/LUN) 上去,后果很严重。和我以前描述过的 4k Offset 问题本质上是一样的。只是这个是针对文件系统的。
那么,如何校正这个 ”对齐偏移量” 呢?
存储厂商的推荐是如果用 Snap View / SAN Copy 等存储级别的操作的话,不要折腾,用系统默认的就成,否则,用主机端的解决方案。
主机端的解决方案分为 Windows 32位、Windows 64 位、Linux、VMware 几种。
1) 对于 32 位的 Windows ,使用 Windows 系统资源包的 diskpar.exe 来设定 offset ( 据说 Windows 2003 SP1 上的 diskpart.exe 已经具备了 diskpar.exe 的功能。refer)
2)对于 64 位的 Windows ,GPT(GUID Partition Table)类型的分区默认有 32M 保留区,MBR 类型的分区自动校准。不存在这个问题。这就是 64位 的 Windows 众多优点之一啊。
3) 对于 Linux ,fdisk /dev/{devicename} 然后进入 expert 模式, 然后输入 b …
4) 对于 VMware,分为两种情况。虚拟机层(用虚拟机下操作系统的方案) 以及 ESX 服务器层 (fdisk).
上面几个步骤描述不详细,更详细的介绍你需要寻找一份白皮书: EMC CLARiion Best Practices for Fibre Channel Storage ,这个白皮书有针对 Flare 不同版本的,Flare 2.6 对这个问题有了比较好的改进。
是的,有的时候白皮书就在那里,只是没有人注意,没有看而已。
–EOF–