我在 DBAnotes.net 上记录过不少比较大的网站架构分析(eg: eBay [1], eBay [2]) ,Amazon 一直找不到太多的资料。国庆期间读到了一篇关于 Amazon Dynamo 的论文,非常精彩。Amazon Dynamo 这个高可用、可扩展存储体系支撑了Amazon 不少核心服务.
先看一个示意图:
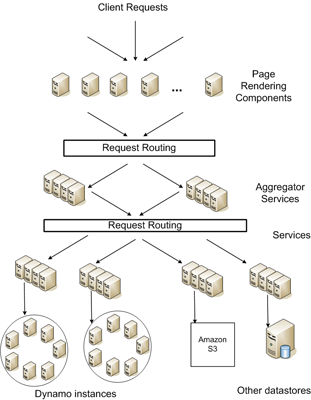
从上图可以看出,Amazon 的架构是完全的分布式,去中心化。存储层也做到了分布式。
Dynamo 概述
Dynamo 的可扩展性和可用性采用的都比较成熟的技术,数据分区并用改进的一致性哈希(consistent hashing)方式进行复制,利用数据对象的版本化实现一致性。复制时因为更新产生的一致性问题的维护采取类似 quorum 的机制以及去中心化的复制同步协议。 Dynamo 是完全去中心化的系统,人工管理工作很小。
强调一下 Dynamo 的”额外”特点:
1) 总是可写
2) 可以根据应用类型优化
关键词
Key: Key 唯一代表一个数据对象,对该数据对象的读写操通过 Key 来完成.
节点(node):通常是一台自带硬盘的主机。每个节点有三个 Java 写的组件:请求协调器(request coordination)、成员与失败检测、本地持久引擎(local persistence engine)
实例(instance);每个实例由一组节点组成,从应用的角度看,实例提供 IO 能力。一个实例上的节点可能位于不同的数据中心内, 这样一个数据中心出问题也不会导致数据丢失。
上面提到的本地持久引擎支持不同的存储引擎。Dynamo 上最主要的引擎是 Berkeley Database Transactional Data Store(存储处理数百K的对象更为适合),其他还有 BDB Java Edition、MySQL 以及 一致性内存 Cache 等等。
三个关键参数 (N,R,W)
第一个关键参数是 N,这个 N 指的是数据对象将被复制到 N 台主机上,N 在 Dynamo 实例级别配置,协调器将负责把数据复制到 N-1 个节点上。N 的典型值设置为 3.
复制中的一致性,采用类似于 Quorum 系统的一致性协议实现。这个协议有两个关键值:R 与 W。R 代表一次成功的读取操作中最小参与节点数量,W 代表一次成功的写操作中最小参与节点数量。R + W>N ,则会产生类似 quorum 的效果。该模型中的读(写)延迟由最慢的 R(W)复制决定,为得到比较小的延迟,R 和 W 有的时候的和又设置比 N 小。
(N,R,W) 的值典型设置为 (3, 2 ,2),兼顾性能与可用性。R 和 W 直接影响性能、扩展性、一致性,如果 W 设置 为 1,则一个实例中只要有一个节点可用,也不会影响写操作,如果 R 设置为 1 ,只要有一个节点可用,也不会影响读请求,R 和 W 值过小则影响一致性,过大也不好,这两个值要平衡。对于这套系统的典型的 SLA 要求 99.9% 的读写操作在 300ms 内完成。
–待续–
更多阅读:Dynamo学习 — http://donghao.org/2008/10/dynamoni.html



