昨天在家看了《盲井》,就像期待的那样沉重。今天想想,回味出来两个字:「回家」。
互联网传来的消息也只有两个字:雪灾。根深蒂固的家的传统观念…一年一度的人口大迁徙偏偏碰上这五十年(百年)不遇的雪灾…年,这个中国人永远摆脱不了的节日啊
上苍保佑! 上苍保佑回家的人们
–EOF–
昨天在家看了《盲井》,就像期待的那样沉重。今天想想,回味出来两个字:「回家」。
互联网传来的消息也只有两个字:雪灾。根深蒂固的家的传统观念…一年一度的人口大迁徙偏偏碰上这五十年(百年)不遇的雪灾…年,这个中国人永远摆脱不了的节日啊
上苍保佑! 上苍保佑回家的人们
–EOF–
又有机会爆料国内 Web 2.0 网站的架构了。这次是 Yupoo! 。非正式的采访了一下 Yupoo!(又拍网) 的创建人之一的 阿华(沈志华)同学,了解了一些小道消息。
作为国内最大的图片服务提供商之一,Yupoo! 的 Alexa 排名大约在 5300 左右。同时收集到的一些数据如下:
带宽:4000M/S (参考)
服务器数量:60 台左右
Web服务器:Lighttpd, Apache, nginx
应用服务器:Tomcat
其他:Python, Java, MogileFS 、ImageMagick 等
首先看一下网站的架构图:
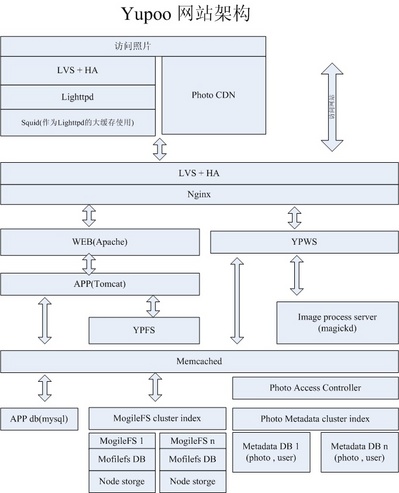
该架构图给出了很好的概览(点击可以查看在 Yupoo! 上的大图和原图,请注意该图版权信息)。
Squid 与 Tomcat 似乎在 Web 2.0 站点的架构中较少看到。我首先是对 Squid 有点疑问,对此阿华的解释是”目前暂时还没找到效率比 Squid 高的缓存系统,原来命中率的确很差,后来在 Squid 前又装了层 Lighttpd, 基于 url 做 hash, 同一个图片始终会到同一台 squid 去,所以命中率彻底提高了”
对于应用服务器层的 Tomcat,现在 Yupoo! 技术人员也在逐渐用其他轻量级的东西替代,而 YPWS/YPFS 现在已经用 Python 进行开发了。
名次解释:
【Updated: 有网友留言质疑 Python 的效率,Yupoo 老大刘平阳在 del.icio.us 上写到 “YPWS用Python自己写的,每台机器每秒可以处理294个请求, 现在压力几乎都在10%以下”】
接下来的 Image Process Server 负责处理用户上传的图片。使用的软件包也是 ImageMagick,在上次存储升级的同时,对于锐化的比率也调整过了(我个人感觉,效果的确好了很多)。”Magickd“ 是图像处理的一个远程接口服务,可以安装在任何有空闲 CPU资源的机器上,类似 Memcached的服务方式。
我们知道 Flickr 的缩略图功能原来是用 ImageMagick 软件包的,后来被雅虎收购后出于版权原因而不用了(?);EXIF 与 IPTC Flicke 是用 Perl 抽取的,我是非常建议 Yupoo! 针对 EXIF 做些文章,这也是潜在产生受益的一个重点。
原来 Yupoo! 的存储采用了磁盘阵列柜,基于 NFS 方式的,随着数据量的增大,”Yupoo! 开发部从07年6月份就开始着手研究一套大容量的、能满足 Yupoo! 今后发展需要的、安全可靠的存储系统“,看来 Yupoo! 系统比较有信心,也是满怀期待的,毕竟这要支撑以 TB 计算的海量图片的存储和管理。我们知道,一张图片除了原图外,还有不同尺寸的,这些图片统一存储在 MogileFS 中。
对于其他部分,常见的 Web 2.0 网站必须软件都能看到,如 MySQL、Memcached 、Lighttpd 等。Yupoo! 一方面采用不少相对比较成熟的开源软件,一方面也在自行开发定制适合自己的架构组件。这也是一个 Web 2.0 公司所必需要走的一个途径。
非常感谢一下 Yupoo! 阿华对于技术信息的分享,技术是共通的。下一个能爆料是哪家?
–EOF–
前提: OpenSSH 配置完毕。并且,目标端到源端通过 SSH 登录无需提示密码验证. (参见我以前的也是关于 rsync 的废话)
下载 AIX 5L Expansion Pack CD 中的 rsync,这个版本稍微有点低。其实也足够了,不过如果和更高版本混用的话,会报告另外一个错误:
sync: connection unexpectedly closed (24 bytes read so far)
rsync error: error in rsync protocol data stream (code 12) ...
在 AIX 上 rsync 需要依赖 Popt–A C library for parsing command line parameters,通过 rpm 命令安装即可. 现在的 AIX 系统默认应该就有安装 rpm (AIX-rpm) 工具包的.
在维基百科上 有 对 rsync 算法的介绍。简单的理解是这么回事:待传送的文件被分成若干定长的文件段,然后对每个文件段做个 “Rolling Checksum”,加上一个强 MD4 校验码, 传送这些信息给接收方, 接收方查找本地类似文件–定长的每个文件段, 对比 Rolling Checksum 与 MD4, 然后传送差异(Delta)数据.
rsync 1996 年才被搞出来,最初是用来对付在低速网络连接上传送差异化文件的。
我一直比较好奇的是 Oracle 的 Data Guard 用什么算法保证所有的归档能无差错传送到远地(?)。
–EOF–
![]()
这几天存储行业比较大的一个新闻是 EMC 宣布在高端 Symmetrix 产品支持 SSD (固态盘, Solid State Drive),注意是基于闪存(FLASH)的固态盘。不到半年前,和一些存储厂商的朋友提及 SSD 仍有人不知为何物,现在似乎一夜之间 SSD 到处都是了。EMC 虽身为市场的领先者,也敢于吃螃蟹,来者不善。

EMC 这次采用的 SSD 是 STEC 公司 Zeus-IOPS 产品线的产品。这一型号号称随机读操作的 IOPS 能达到 52000 个,采用 SLC (single-layer cell ),写也可以达到 17000 个 IOPS。只从这个数字看,单块 SSD 的性能是机械硬盘的 30 倍还多。在可靠性上,SETC 据说实现了 ECC 机制.
现有的机械硬盘的虽说在单位容量上还在不停的增加,但是性能基本上是到了瓶颈,即使用于高端存储的高速硬盘,IOPS 的能力基本上也就是 150 个左右。而 SSD 单块就能提供几万个 IOPS ,且耗电量极小,平均故障间隔时间(MTBF)又是普通硬盘的10倍之多, 这对以期得到高 IOPS 的 DBA 来说, 简直是银弹。
但是(什么都怕这个”但是”),但是 SSD 的有它固有的缺点。其中一个就是可擦写次数(这个在几个新闻稿里面可算是一笔带过的),尤其是基于 Flash 的 SSD。传统磁盘虽然有它的缺陷,但是可擦写次数几乎是无限次的。
听听来自竞争对手的声音或许也能让我们多点心眼。HDS 的 CTO Hu Yoshida 在 Blog 上撰文,提出了他对 SSD 能否被市场接受的三点疑问:
如果说前两条只是竞争对手的 FUD 的话,那么最后一条还是会令 EMC 销售很头疼,如何让客户消除这个疑虑是有些难度的。STEC 官方的技术参数是可擦写次数能达到 200 万次。这样看的话,在高端存储上用 SSD 还是有比较合适的应用场景:在 EMC 提倡的 “智能分层存储” 前提下由 SSD 提供密集读的操作能力。
–EOF–